

Definition of a Prompt in AI Tools
A prompt in AI tools is a structured input sequence provided to a computational model to initiate processing and generate an output. It is designed to encode user intent into a form that can be interpreted within the model’s representational and computational framework.
Within AI systems, a prompt in AI tools is represented as an ordered sequence of tokens, symbols, or formatted elements that function as the initial condition for inference. It serves as the primary interface through which external input is introduced into the system for processing.
This discussion focuses specifically on the structural definition and input composition of prompts, distinct from the processes involved in interpretation, inference, or output generation.
This concept is further examined in: How AI Tools Interpret Prompts
A prompt in AI tools is not restricted to natural language. It may consist of multiple input forms, including symbolic, structured, or multimodal representations, depending on system architecture.
Structural Nature of Prompts
Prompts are observed as structured entities composed of multiple interrelated components. These components are not fixed or universally standardized but are commonly identified as functional layers that contribute to how the input is interpreted within the model.
These layers are not strictly isolated; rather, they may overlap or interact depending on how the prompt is constructed and processed. These layers collectively define the structural conditions under which the prompt is interpreted.
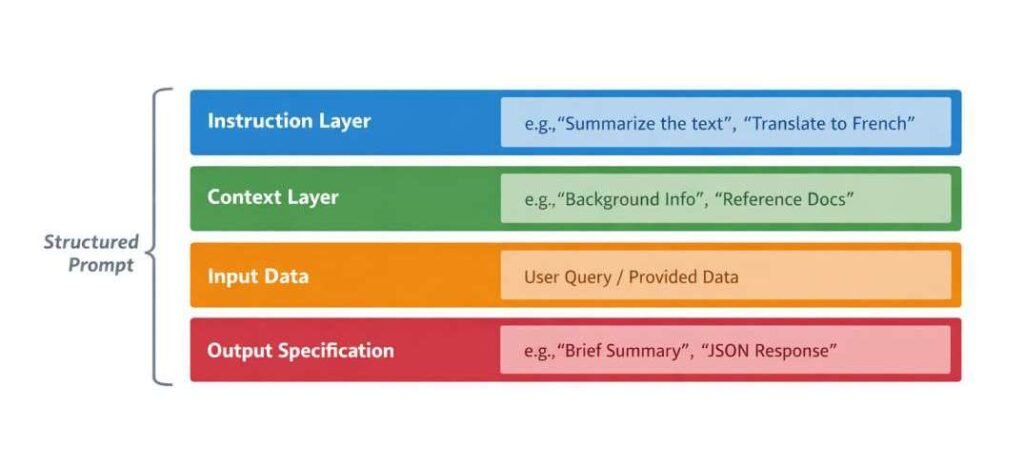
Instruction Layer
The instruction layer defines the intended operation or transformation to be performed by the system.
It is typically expressed as a directive component within the prompt and establishes the primary interpretive frame.
This layer may define:
- Task type
- Transformation condition
- Processing objective
The interpretation of this layer is dependent on surrounding contextual information and is not evaluated as an isolated component.
This structural component operates in conjunction with contextual information and input data, contributing to how the prompt is interpreted during model processing.
Context Layer
The context layer provides supplementary information that conditions how the instruction layer is interpreted within the overall prompt structure.
It establishes constraints, background conditions, or domain-specific framing that influence how token relationships are evaluated.
This layer may include:
- Descriptive background information
- Domain-relevant constraints
- Conditional parameters
The context layer modifies interpretive scope and may alter how identical instruction structures are processed under different conditions.
This structural component operates in conjunction with instruction signals and input data, influencing how contextual relationships are formed during processing.
Input Data Segment
The input data segment contains the primary content upon which processing is performed during model inference.
This segment functions as the core informational payload within the prompt and is evaluated in relation to both instruction and context layers.
It may appear in forms such as:
- Continuous text sequences
- Lists or structured entries
- Code fragments or symbolic expressions
- Tabular or schema-based data
The interpretation of input data is dependent on both its internal structure and its positional relationship within the prompt.
This structural component operates in conjunction with instruction and context layers, contributing to how informational content is evaluated within the prompt.
Output Specification Layer (Optional)
Some prompts include an explicit output specification layer that defines structural or formatting constraints for the generated output.
This layer may define:
- Structural format
- Length boundaries
- Formatting conditions
This layer does not directly influence internal processing logic but may constrain how output is represented after inference.
This layer may define:
- Structural format (e.g., paragraph, list, schema)
- Length boundaries
- Formatting constraints
This structural component operates in conjunction with other prompt elements, constraining how generated output is structured without redefining internal interpretation.
Interdependence of Prompt Layers
The structural layers within a prompt are interdependent and function as a unified sequence rather than isolated components.
- The instruction layer is interpreted in relation to context
- The input data segment is evaluated based on both instruction and context
- The output specification layer constrains representation without redefining interpretation
These relationships indicate that prompt structure is relational rather than modular, and meaning is derived from the interaction between components.
Following structural composition, prompts undergo transformation into internal representations for computational processing.
Tokenization and Internal Representation
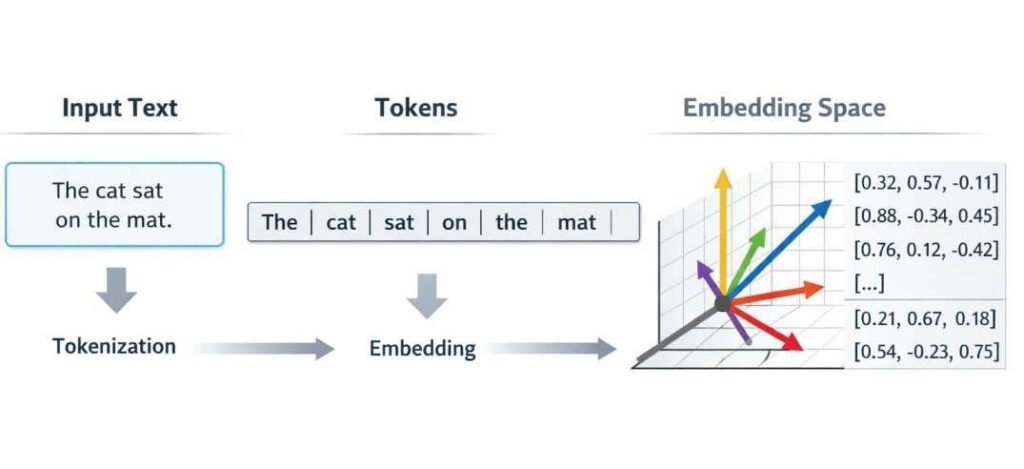
Before processing, prompts are transformed into token sequences through a representation step known as tokenization.
This transformation process is also examined in: How AI Tools Transform Raw Data
Tokenization segments the input into smaller computational units, referred to as tokens. These tokens may represent:
- Words or subword units
- Characters or symbols
- Structured elements depending on input format
Each token is mapped to a numerical representation within the model’s internal vector space. In addition to token identity, positional information is encoded to preserve sequence order.
The internal representation does not retain formatting in a literal or visual sense. Instead, it encodes relationships between tokens based on:
- Sequence position
- Co-occurrence patterns
- Contextual dependencies
Meaning is therefore represented through relational encoding rather than visual formatting.
This representational process operates in conjunction with sequential ordering and contextual dependency, influencing how token relationships are interpreted during processing.
Sequential Dependency and Ordering
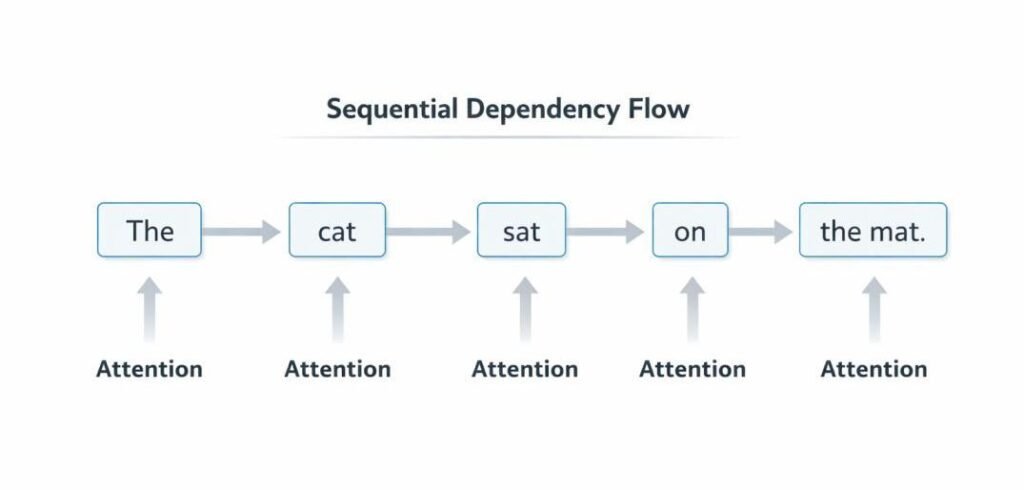
Prompts are inherently sequential structures in which the order of tokens influences how interpretation is formed.
- Earlier segments establish initial interpretive conditions
- Intermediate segments refine or constrain interpretation
- Later segments may introduce additional conditions or output constraints
Token order contributes to dependency formation, where the interpretation of a given token is conditioned by preceding tokens.
This sequential dependency indicates that prompts are processed as ordered relational structures rather than unordered collections of elements.
This mechanism is related to how responses are generated sequentially in AI systems: AI Text Generation Process
Input Format Variants
Prompt structures are observed in multiple input formats depending on system configuration and interface design.

Plain Text Format
A continuous sequence of text without explicit structural markers.
Segmentation in this format is inferred from linguistic and positional patterns within the sequence.
Delimited Format
A format in which components are separated using explicit markers.
Common delimiters include:
- Colons
- Line breaks
- Section headers
These markers introduce structural boundaries that influence how segments are interpreted within the prompt.
Structured Format
Prompts may be organized using predefined schemas that explicitly define relationships between elements.
Observed structures include:
- Key–value pairs
- JSON-like representations
- Tabular formats
These formats support consistent parsing and reduce ambiguity in structural interpretation.
Multi-Turn Format
Prompts may exist as part of sequential interactions in which prior inputs are incorporated into the current prompt.
In such cases, the prompt represents an accumulated sequence of inputs rather than a single isolated instance.
Earlier inputs function as contextual extensions that influence the interpretation of subsequent inputs.
Prompt Length and Boundary Conditions
Prompts are subject to system-defined constraints, often expressed as token limits.
These constraints define:
- Maximum input size
- Allocation between input and output tokens
- Truncation behavior when limits are exceeded
When limits are reached, portions of the prompt may be excluded from processing.
Modal Variations of Prompts
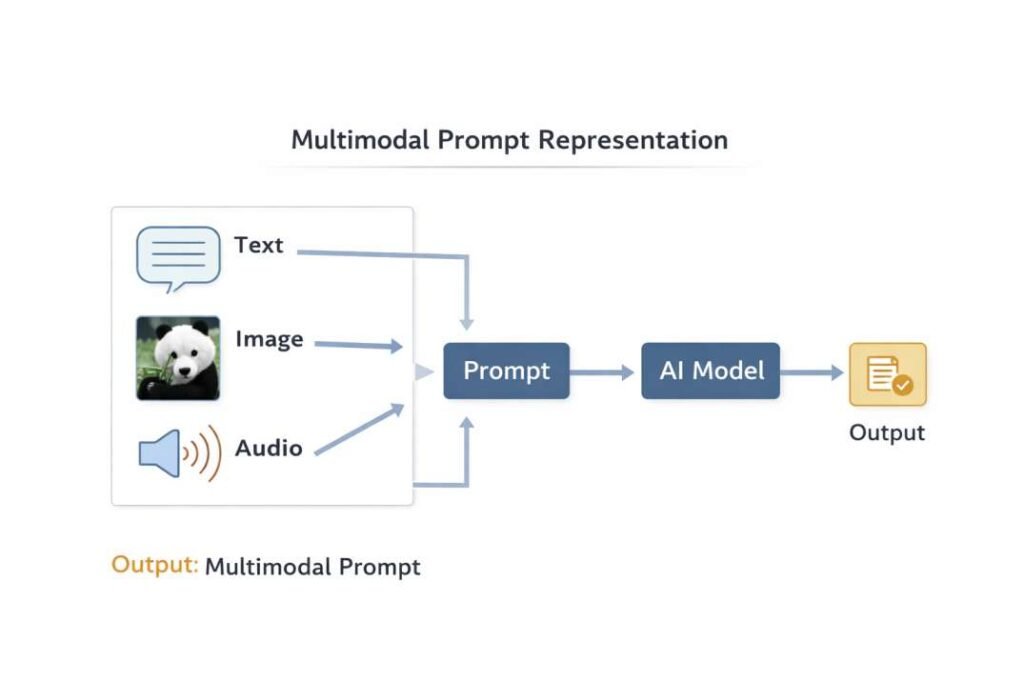
Prompts are not limited to text-based inputs. In multimodal systems, prompts may include multiple data types.
Observed modalities include:
- Text inputs
- Image inputs
- Audio inputs
- Combined multimodal sequences
Each modality is encoded into a representation compatible with the system’s architecture, allowing different input types to be integrated into a unified processing sequence.
Prompt Interpretation in AI Systems
Prompt interpretation is a process in which the model evaluates token sequences to identify patterns and relationships.
This process is based on:
- Statistical associations between tokens
- Contextual dependencies across the sequence
- Learned representations derived from training data
A given prompt may correspond to multiple potential interpretations, with resolution determined by probabilistic weighting of token relationships.
This probabilistic evaluation process is also examined in: Why AI Tools Give Different Answers
The prompt functions as an input signal that is evaluated within this probabilistic framework rather than as a fixed or deterministic command.
Representation vs Formatting Distinction
The structural appearance of a prompt does not correspond directly to its internal computational representation.
- Visual formatting (e.g., line breaks, spacing) is not preserved as-is
- Structural relationships are encoded through token sequences and positional information
This distinction indicates that interpretation is based on encoded relationships rather than visual layout.
Summary
A prompt in AI tools is a structured input construct composed of interdependent components, including instruction, context, data, and optional output specifications. It is transformed into token sequences and encoded as numerical representations prior to processing.
Prompt interpretation is based on sequential dependencies, relational token structures, and probabilistic evaluation within the model’s computational architecture. Structure, format, ordering, and boundary conditions collectively influence how input is represented and interpreted within AI systems.
Frequently Asked Questions
What is a prompt in AI tools?
A prompt in AI tools is a structured input sequence provided to a computational model to initiate processing. It encodes user intent into a format that can be interpreted within the model’s representational and computational framework.
What components are included in a prompt structure?
A prompt structure commonly consists of interrelated components, including an instruction layer, a context layer, an input data segment, and an optional output specification layer. These components function together as a unified input sequence.
How is a prompt represented inside an AI system?
A prompt is represented as an ordered sequence of tokens that are mapped to numerical representations within the model’s internal vector space. These representations encode relationships based on sequence position and contextual dependencies.
What is tokenization in prompt processing?
Tokenization is the process through which a prompt is segmented into smaller computational units known as tokens. These tokens form the representational units used during model processing.
How does prompt structure influence interpretation?
Prompt structure influences interpretation through the interaction of its components. The arrangement and relationship between instruction, context, and input data affect how token dependencies are evaluated during processing.
What input formats can prompts have in AI systems?
Prompts may exist in multiple formats, including plain text, delimited structures, schema-based representations, and multi-turn sequences. Each format defines how structural boundaries and relationships are expressed.
What is sequential dependency in prompts?
Sequential dependency refers to the condition where the interpretation of tokens is influenced by their position within the sequence. Earlier tokens establish interpretive conditions that affect subsequent tokens.
References
Foundational research relevant to prompt structure, tokenization, and sequence-based model interpretation includes:
- Vaswani, A., et al. (2017). Attention Is All You Need.
https://arxiv.org/abs/1706.03762 - Brown, T. B., et al. (2020). Language Models are Few-Shot Learners.
https://arxiv.org/abs/2005.14165 - Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units.
https://arxiv.org/abs/1508.07909 - Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer.
https://arxiv.org/abs/1808.06226 - Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning.
https://arxiv.org/abs/2104.08691 - Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A Neural Probabilistic Language Model.
https://www.jmlr.org/papers/v3/bengio03a.html
These works define the structural and representational foundations of prompt processing in AI systems.
- Top 10 Free AI Tools for Beginners (2026 Guide) - April 3, 2026
- How to Use ChatGPT for Beginners (Step-by-Step Guide) - March 31, 2026
- Why AI Tools Fail Outside Training Conditions - March 29, 2026