
Quick Answer:
Conflicting instructions mean two or more directions that compete with or contradict each other, making it difficult to satisfy all requirements at the same time.
In AI prompts, conflicting instructions occur when a model receives competing requirements without a clear priority—for example, asking it to be “detailed but concise,” “casual but formal,” or “highly technical but beginner-friendly.”
These conflicts can increase output variability, editing time, and workflow inconsistency.
Clear instruction priority and one primary objective generally produce more stable outputs.
Table of Contents
The Problem That Started This Analysis
Conflicting instructions in AI prompts are one of the most common — and least visible — causes of output instability in production workflows.
On the fifth repeated run of the same prompt, GPT-4o violated both the tone instruction and the word-count limit simultaneously. The output required 18 minutes of manual correction before it was publishable.
The same pattern appeared across multiple publishing tasks — and it was consistent enough to test deliberately.
Across repeated workflow tests, higher instruction conflict was consistently associated with greater output variability and longer correction time.
This instability is closely related to why AI models sometimes ignore instructions in complex prompts.
Key Takeaway: High-constraint prompts consistently increased editing overhead during repeated workflow testing. Reducing instruction conflict was one of the most effective changes observed during this workflow testing.
What Is Instruction Conflict in AI Prompts?
Instruction conflict occurs when a prompt contains two or more requirements that compete with each other. Instead of receiving a clear priority order, the AI attempts to satisfy all instructions simultaneously.
Common examples include:
- Be detailed but concise
- Use a casual but formal tone
- Write for experts and beginners at the same time
When these requirements conflict, AI systems often produce blended outputs that only partially satisfy each instruction. Rather than clearly prioritizing one objective, the model often generates a compromise between competing requirements.
For example, a prompt that requests an executive summary with deep technical detail may produce an output that is neither concise enough for executives nor detailed enough for specialists.
In production workflows, instruction conflict often increases output variability, editing overhead, and correction time. This makes prompt reliability harder to maintain across repeated runs and larger-scale content operations.
Why Editing Overhead Is the Real Metric
Most prompt engineering discussions focus on output quality. This workflow analysis focuses on something more operationally relevant for teams: correction cost per output.
For teams using AI in production workflows — content, documentation, research support — it becomes a direct operational expense. When editing takes longer than generation, the workflow loses efficiency.
In production publishing environments, this delay compounds across approvals, revisions, and content scheduling workflows.
In larger production environments, one-off prompts are rarely enough to maintain reliable workflow consistency across repeated tasks.
“Reducing correction overhead per output can significantly improve workflow efficiency at scale.”
This pattern appeared consistently across the workflow tests — and it is the most actionable takeaway from this analysis.
Instruction Conflict Flow
More Constraints
↓
Instruction Competition
↓
Output Instability
↓
Manual Correction
↓
Higher Workflow Cost
Test Setup
Models tested:
- GPT-4o (ChatGPT Web, default settings)
- Claude 3.5 Sonnet (Claude.ai Web, default settings)
Method:
- 5 repeated runs per prompt using identical inputs
- Default UI settings — no temperature or parameter adjustments
- Outputs were manually reviewed for tone consistency, structural compliance, formatting stability, and instruction adherence.
Variables tracked:
- Word-count compliance
- Tone consistency
- Formatting stability
- Manual editing time per output
Prompt categories:
- Low-conflict (2 constraints)
- Moderate-conflict (4 constraints)
- High-conflict (6+ constraints)
A run was classified as “unstable” if it violated two or more constraints simultaneously, or required significant manual correction before publishing.
Note: This testing was conducted across publishing-oriented tasks — content drafting, rewriting, and summarization. Results may differ for other use cases or under API-level parameter control.
Observed Workflow Patterns
| Conflict Level | Typical Behavior | Editing Impact | Recommended Action |
|---|---|---|---|
| Low | Stable structure and consistent outputs | Low editing time | Maintain one primary objective |
| Moderate | Some tone and formatting drift | Medium correction overhead | Reduce competing instructions |
| High | Unstable responses and blended outputs | High correction cost | Use explicit instruction priorities |
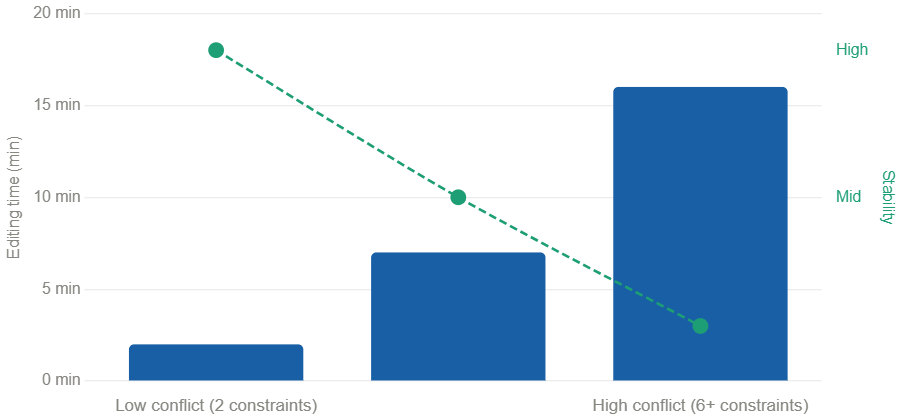
The most significant pattern: editing time generally increased as prompt constraint complexity increased. In high-conflict conditions, formatting corrections alone took longer than the initial content generation.
Case 1: Competing Audience and Tone Constraints
Prompt used:
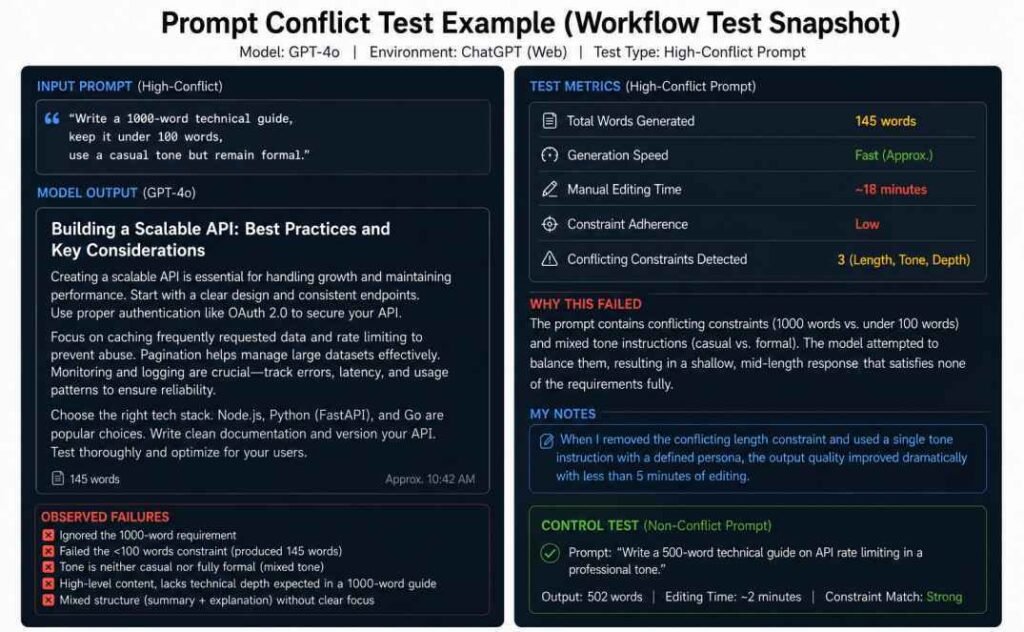
“Write a concise executive briefing on zero-trust security with enough technical depth for cybersecurity engineers, use a casual tone but remain formal.”
This prompt contains two direct conflicts:
- Audience depth: leadership-level brevity vs. technical detail for engineers
- Tone: conversational phrasing vs. formal enterprise communication
Outputs across 3 runs:
| Run # | Word Count | Tone Consistency | Structural Compliance | Editing Required |
|---|---|---|---|---|
| #1 | 145 | Partial | Moderate | ~12 min |
| #2 | 380 | Weak | Low | ~18 min |
| #3 | 92 | Inconsistent | Incomplete | ~9 min |
None of the three runs produced the same structure. None fully satisfied any single constraint.
What happened instead of choosing:
In several runs, the model appeared to “compromise” between conflicting instructions instead of following one clearly. The result was usually an awkward middle-ground output that satisfied none of the constraints completely.
The model produced outputs that landed between the conflicting requirements — long enough to feel incomplete, short enough to lack depth, formal enough to feel stiff, casual enough to feel inconsistent.
Similar instability appears in overloaded multi-step prompts where too many instructions compete simultaneously.
Most users do not explicitly tell the model which instruction matters most. When prompts contain conflicting requirements, the model often tries to balance them instead of prioritizing one clearly. Because transformer models predict probabilistic next-token patterns rather than applying deterministic rule resolution, conflicting instructions often produce blended outputs instead of strict prioritization.
The screenshot below shows one of the failed generations during manual review.
Case 2: Audience Conflict Embedded in the Prompt
Prompt used:
“Write a concise beginner guide for cybersecurity professionals. Keep the explanation highly technical but easy for non-technical readers.”
This prompt targets two incompatible audiences simultaneously — the conflict is not in the constraints, but in the audience definition itself.
Observed behaviors across 5 runs:
- Word count shifted between 180–420 words
- Audience targeting shifted mid-response in 2 of 5 runs
- Tone moved between enterprise phrasing and basic explainer language within the same paragraph
- Formatting required manual correction in 4 of 5 runs
This type of conflict was harder to fix after the fact — because the issue was structural, not stylistic.
When Additional Constraints Reduced Reliability
In repeated workflow testing, competing constraints consistently reduced output reliability across publishing-oriented tasks.
This blending behavior also explains why AI outputs sometimes sound confident even when the content is structurally weak.
In these workflow tests, reliability often decreased once prompts accumulated around 5–6 competing high-priority instructions. Beyond that point, additional constraints typically increased output variability rather than improving precision.
In workflow terms: more constraints often produced more editing time, not better output.
The Conflict-Fix Matrix
| Conflict Type | What Usually Happens | Better Fix |
|---|---|---|
| Tone conflict | The model mixes styles and produces inconsistent writing | Separate tone and formatting instructions by priority |
| Scope conflict | Important details get compressed or skipped unevenly | Break the task into smaller sequential prompts |
| Constraint conflict | The model ignores the instruction that is harder to follow | Use clear priority rules or conditional instructions |
| Audience conflict | The writing shifts between beginner and expert language | Define primary reader before technical depth requirements |
What Reduced Instability
After identifying the failure patterns, I restructured the same tasks using explicit instruction priority.
Before (unstable):
“Be detailed but concise. Use a casual but formal tone.”
After (logic-gate structure):
“Analyze the complexity of the input. IF the topic requires detailed explanation, prioritize depth. IF it is straightforward, prioritize brevity. Use a professional tone throughout.”
Results after restructuring:
| Workflow Metric | Before | After |
|---|---|---|
| Output Stability | Variable across runs | Consistent |
| Avg Editing Time | ~15 min | ~4 min |
| Tone Consistency | Inconsistent | Stable |
| Formatting Compliance | Variable | Reliable |
The following structures produced the most stable outputs in repeated workflow testing:
- One primary objective per prompt
- Instructions ordered by priority — with the highest-priority requirement stated explicitly
- Explicit conditional logic when multiple output paths were possible
- One clearly defined audience per prompt
- One dominant tone throughout the request
- Separating role, audience, and formatting requirements into distinct instruction blocks
Related Experiment
Prompt restructuring improves instruction quality, but reliable workflows also depend on whether the model continues following earlier instructions throughout a conversation.
EXP-002: Instruction Retention Test documents a real multi-turn conversation showing that a single instruction remained active across multiple unrelated prompts under the tested conditions. Together, these findings suggest that clear instruction design and instruction retention both contribute to more consistent AI behavior.
→ View EXP-002: Instruction Retention Test
By contrast, prompts that combined tone, length, formatting, and audience constraints simultaneously — without clear priority rules — consistently produced the least stable outputs.
Appendix: Representative Test Prompts and Outputs
Test Prompt A — High Conflict
Prompt:
“Write a concise executive briefing on zero-trust security with enough technical depth for cybersecurity engineers, use a casual tone but remain formal.”
Output snippet (Run #2, 380 words):
“Cybersecurity requires organizations to maintain scalable digital protection strategies while also helping users stay secure in rapidly evolving online environments…”
Deviation:
Tone shifted between formal enterprise phrasing and conversational advisory language within the same response.
Test Prompt B — Audience Conflict
Prompt:
“Write a concise beginner guide for cybersecurity professionals. Keep it highly technical but easy for non-technical readers.”
Output snippet (Run #3):
“Zero-trust architecture ensures that no user or device is trusted by default — think of it like a door that checks your ID every single time, even inside the building.”
Deviation:
Mid-response shift from technical framing to consumer-level analogy. Formatting inconsistent with professional documentation standard.
Test Prompt C — Low Conflict (Control)
Prompt:
“Write a 400-word professional summary of zero-trust security for a technical audience.”
Output across 5 runs:
Word count stable (380–415 words). Tone consistent. No manual formatting correction required in any run.
Editing time: ~2 minutes average across all 5 runs.
This sensitivity to phrasing is closely related to how AI tools interpret prompt structure differently across runs.
Limitations
- Sample size is limited to publishing-oriented workflow tasks
- Testing conducted on default web UI — API-level control may produce different results
- Editing time measurements reflect one workflow and are not standardized
- Findings should not be generalized to all AI task types or models
These observations reflect one workflow environment and should be interpreted as operational testing notes rather than formal benchmark research.
Frequently Asked Questions
What causes instruction conflict in AI prompts?
Instruction conflict usually occurs when a prompt contains competing constraints, objectives, or audience requirements that cannot easily be satisfied at the same time.
Why do conflicting prompts reduce AI reliability?
Conflicting instructions can make multiple requirements compete for priority, increasing output variability and reducing consistency across repeated runs.
How many constraints should a prompt contain?
There is no universal limit. However, repeated workflow testing in this analysis showed that reliability often decreased once prompts accumulated around five or six competing high-priority instructions.
How can teams reduce instruction conflict?
Teams can improve reliability by defining one primary objective, assigning instruction priority, separating audiences clearly, and testing prompts across repeated runs.
What This Means for Teams
If your team is using AI to produce content at volume, instruction conflict is a direct operational cost — not just a quality concern.
Before deploying any prompt in a repeatable workflow, ask:
- Does this prompt contain instructions that cannot be satisfied simultaneously?
- Is there one clearly defined primary audience?
- Are the most important constraints explicitly prioritized?
- Has this prompt been tested across at least 3 repeated runs?
Prompts that pass these checks consistently produced more stable outputs — and required significantly less correction overhead.
Conclusion
In these workflow tests, conflicting instructions frequently reduced output consistency and increased correction time. In practice, simpler prompt structures produced more stable results than heavily constrained prompts.
The most reliable improvements came from:
- defining one primary objective,
- setting clear instruction priority,
- and avoiding audience or tone conflicts inside the same request.
For production workflows, correction overhead per output is more actionable than output quality scores alone. If teams want more stable AI-assisted workflows, reducing instruction conflict is one of the simplest places to start.
References
- Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
- OpenAI (2023). GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
Testing conducted by Soumen Chakraborty, AIToolsUsageGuide.org
All prompt tests run on default web UI. No API parameter modifications applied.

Independent AI Behavior Researcher
Soumen Chakraborty is the founder of AI Tools Usage Guide and an independent AI Behavior Researcher. His research examines how AI systems behave in practical workflows, with a focus on instruction-following failures, prompt reliability, hallucination risks, context loss, and output reliability.