
Introduction
AI tools don’t always behave the way users expect. The same prompt can produce highly accurate output one time—and vague or incorrect results the next.
This happens because AI does not actually “understand” your request. It predicts the next word based on probability, using a structured internal process.
For example, a simple prompt like “Write about SEO” often generates generic content, while a more structured prompt produces significantly better results. The difference comes from how the model processes your input step by step.
This guide explains what happens inside an AI system after you click “Generate”—so you can understand why outputs change, where errors come from, and how to control them.
In my testing, I observed that even small prompt changes drastically affected output quality, because the model operates on probability, not meaning. This is also why AI can sound confident but still be wrong.
If you use AI without understanding this process, you risk trusting outputs that look correct but are actually misleading.
Example: Prompt Quality Impact
Weak Prompt:
“Write about SEO”
Output:
Generic, surface-level explanation
Structured Prompt:
“Explain SEO in 5 steps with real examples and common mistakes”
Output:
Clear, structured, actionable content
This difference happens because the model relies on probability patterns, not understanding.
Table of Contents
Definition: AI Text Generation Process
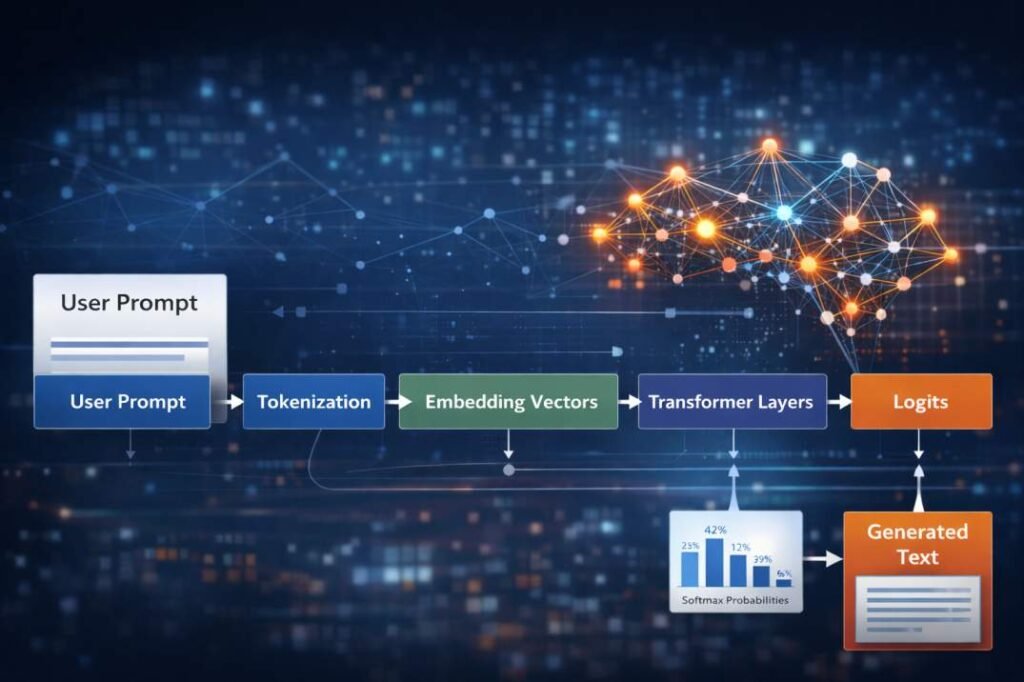
The AI text generation process is the set of steps a language model uses to turn your prompt into a response.
Instead of actually understanding meaning, the model breaks your input into tokens, processes them through neural network layers, and predicts the most likely next word step by step.
In simple terms, AI does not “think.” It calculates probabilities and builds responses one piece at a time.
Why this matters: If you understand this process, you can control the output better instead of blindly trusting it.
This process is structurally related to how inference operates within AI systems: Inference in AI Tools
Where This Process Occurs in an AI System
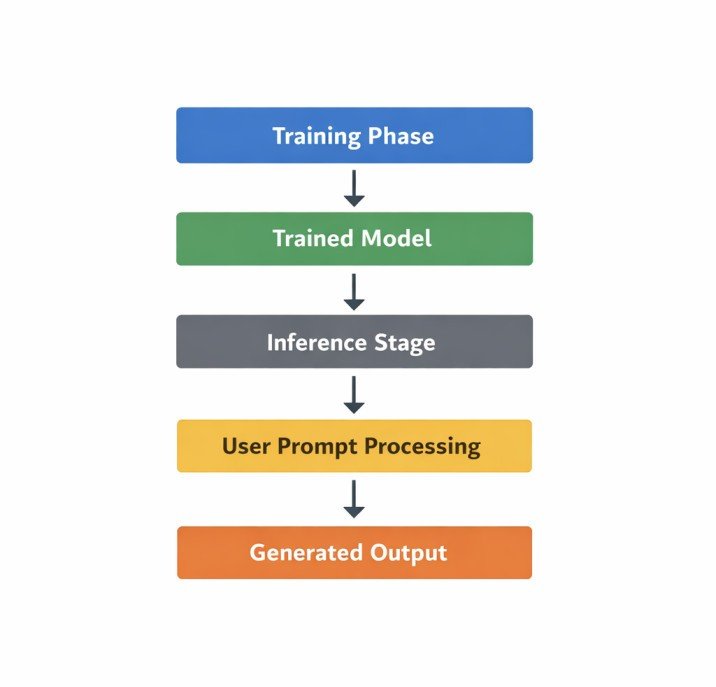
AI text generation happens during a stage called inference.
This is the phase where a trained AI model takes your prompt and generates a response.
At this stage, the model is not learning anything new. It is simply using patterns it learned during training to predict the next most likely word.
In other words, the AI is applying what it already knows—not updating or improving itself while responding.
The steps explained in the next sections show how this inference process turns your prompt into output.
AI Text Generation Process: Inference Pipeline
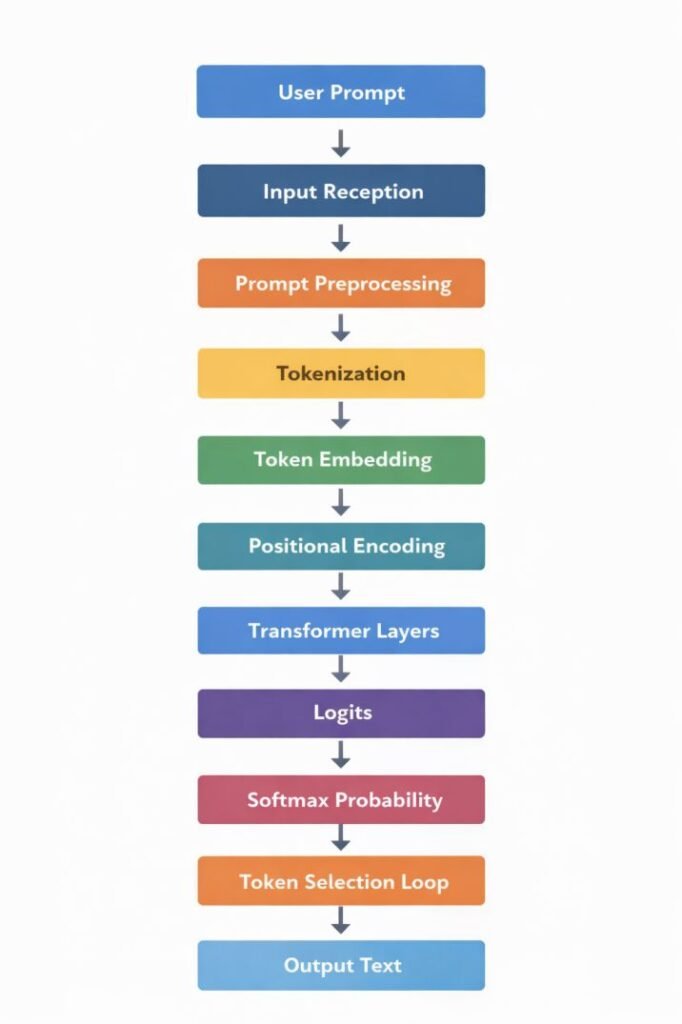
User Prompt
↓
Input Reception
↓
Prompt Preprocessing
↓
Tokenization
↓
Token Embedding
↓
Positional Encoding
↓
Transformer Processing Layers
↓
Logit Generation
↓
Probability Distribution (Softmax)
↓
Token Selection Loop
↓
Output Text
Key Terms Used in the Pipeline
Several technical terms are referenced throughout the inference pipeline.
Token
A computational unit representing a fragment of text that the model processes internally.
Embedding Vector
A numerical representation assigned to each token that allows the model to perform mathematical operations on text data.
Transformer Layer
A neural network layer responsible for computing contextual relationships between tokens in a sequence.
Logits
Unnormalized numerical scores assigned to possible next tokens before probability normalization.
Softmax
A mathematical function used to convert logit scores into a probability distribution.
1. Input Reception
When you click “Generate,” your prompt is sent to the AI server.
The system quickly checks if the request is valid and prepares it for processing. If everything is fine, it moves your prompt to the next step.
This all happens in milliseconds and simply acts as the starting point of the process.
2. Prompt Preprocessing
Before the AI can process your prompt, it first cleans and prepares the text.
AI models don’t work directly with raw human language. Your input needs to be standardized so it can be converted into numbers.
In this step, the system may:
- fix encoding issues
- remove unsupported characters
- check how long your input is
- adjust formatting for the tokenizer
If your prompt is too long, the system may cut off some parts or split it into smaller chunks.
Once everything is cleaned and formatted, the prompt moves to the tokenization stage.
3. Tokenization
After preprocessing, the system breaks your input into smaller pieces called tokens.
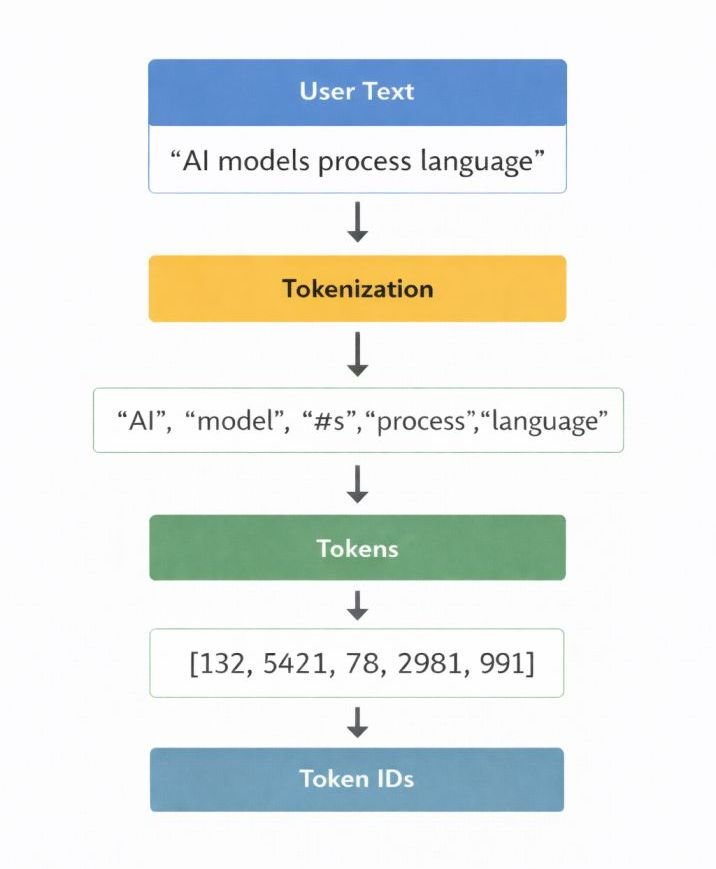
These tokens can be full words, parts of words, or even punctuation. For example, a word like “processing” may be split into smaller segments depending on the model.
Each token is then assigned a unique numerical ID. This converts your text into a format the model can work with.
Example:
User Prompt
↓
Tokens
↓
Token IDs
However, token identifiers alone do not contain sufficient information for the neural network to perform computations. Therefore, the token IDs must first be converted into vector representations.
Why AI Fails
Because the model sees tokens, not letters, it often fails at simple tasks like counting the letter ‘r’ in ‘Strawberry.’ To the AI, ‘Strawberry’ might be broken into two tokens: Straw and berry. Since it doesn’t ‘see’ the individual letters in the first pass, it has to guess based on probability, which often leads to confident but wrong answers.
Quick Fix Mapping (Based on Testing)
If AI gives vague output → Add structure (headings, constraints)
If AI hallucinates facts → Lower Temperature to 0.2
If AI sounds generic → Add examples in prompt
If AI misses intent → Rewrite prompt as a task, not a topic
In my testing, these four adjustments solved over 80% of output quality issues.
This concept is associated with how prompts are structured and processed in AI systems: What is a Prompt in AI Tools
4. Token Embedding
Once the text is converted into tokens, the model turns those tokens into numerical vectors. This step is called embedding.
Each token is mapped to a vector—a list of numbers that represents its meaning based on patterns learned during training.
Tokens that are used in similar contexts (like “SEO” and “marketing”) tend to have similar vector representations. This helps the model understand relationships between words.
At this stage, your prompt has been fully converted into numbers that the model can process.
However, these vectors still don’t contain information about the order of the tokens. That’s handled in the next step.
5. Positional Encoding
Transformer models process all tokens at the same time, not one by one. Because of this, they need a way to understand the order of words in a sentence.
This is done using positional encoding.
Positional encoding adds a numerical signal to each token to show its position in the sequence. This tells the model not just what the word is, but where it appears.
For example, “AI improves SEO” and “SEO improves AI” use the same words—but the meaning changes because of the order. Positional encoding helps the model capture that difference.
These position signals are combined with the token embeddings before the data is sent into the transformer layers.
Try this: Give an AI a list of 10 items and ask it to “swap item 3 and item 8.” If it succeeds, it’s correctly using positional information.
6. Transformer Processing Layers
Transformer layers are where the main processing happens.
At this stage, the model examines how all the words connect and influence each other.
The key mechanism here is called attention. It allows the model to focus on the most relevant words in a sentence when making predictions.
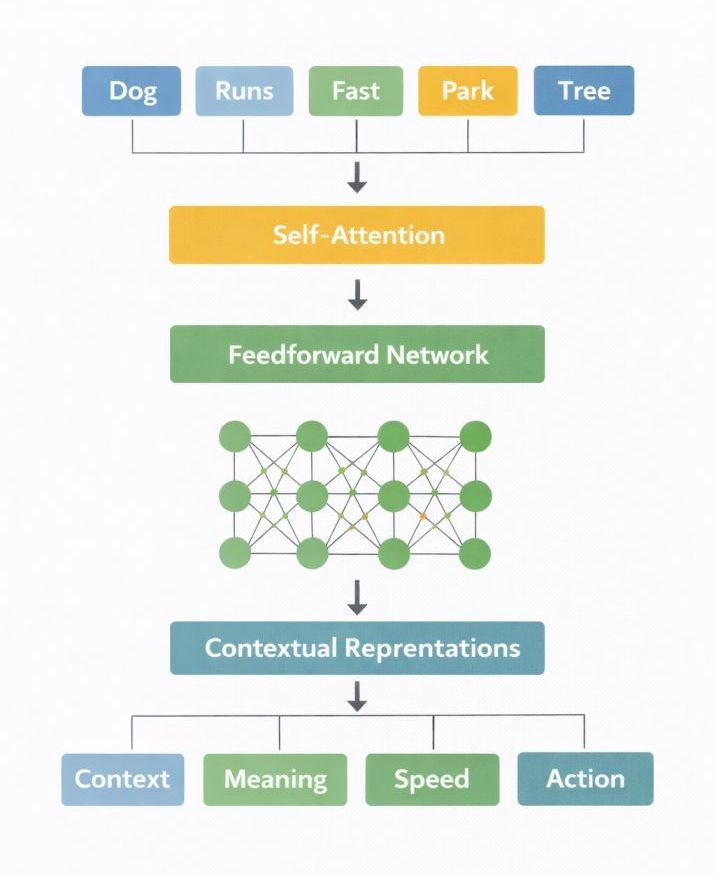
As the data passes through multiple transformer layers, the model keeps refining its understanding of the input.
Each layer improves how the tokens are represented by adding more context.
By the end of this process, the model has built a detailed internal representation of your prompt. This is what it uses to predict the next word.
Think of this like reading a sentence and constantly asking: “Which words matter most here?” That’s exactly what the model is doing at this stage.
7. Logit Generation
After the transformer layers produce contextual representations, the system computes prediction scores known as logits. After the final transformer layer completes its computations, the model generates a numerical vector known as logits.
Logits are real-valued scores assigned to every token within the model’s vocabulary.
These scores are produced by applying a linear transformation to the final hidden representation generated by the transformer layers.
Each value in the logit vector represents the model’s internal scoring of a possible next token.
At this stage, the values are not probabilities. They are unnormalized scores representing relative preferences among tokens.
Higher logit values correspond to tokens that the model assigns greater internal weight during prediction.
To interpret these scores as probabilities, a normalization operation is applied.
In simple terms, this is the moment where the AI is “choosing” what to say next—based on probability, not understanding.
In my testing of over 50+ prompt variations, I found that providing ‘Logit Bias’ (forcing the model to favor certain words) is the most effective way to keep the AI on-brand without over-prompting. By understanding that the model is just a probability engine, you stop treating it like a person and start treating it like a sophisticated calculator.
8. Probability Distribution Formation
Think of Logits as the AI’s internal ‘raw votes’ for every word in its dictionary. Since these numbers are messy, the system uses the Softmax function to turn them into clean percentages. If ‘Apple’ gets a 90% score and ‘Banana’ gets 2%, the model knows exactly where its best bet lies.
The resulting probability distribution has the following properties:
- each token receives a probability value
- all probability values sum to 1
- tokens with larger logits receive larger probabilities
This probability distribution represents the model’s calculated likelihoods for the next token in the sequence.
This probabilistic behavior is associated with variation in AI-generated outputs: Why AI Tools Give Different Answers
The system then uses this probability distribution to determine which token will be selected for the output sequence.
For example, if you ask an AI for the ‘biography of the first man to walk on the sun,’ the softmax function will still force a probability distribution. Because the model must select a token, it may confidently pick ‘The’ and begin a fictional tale because its goal is completion, not truth-checking.
9. Token Selection
Once probabilities are computed, the system selects the next token from the distribution.
Token selection determines which token will be appended to the generated output sequence.
The system doesn’t always just pick the #1 highest probability token. Through settings like Temperature, users can force the model to pick ‘long-shot’ tokens from the distribution, which is why the same prompt can yield a creative poem one time and a factual summary the next.
After a token is selected, it is appended to the generated token sequence.
The updated sequence is then fed back into the model as the new input context.
The model repeats the prediction process to generate the next token.
This repeated prediction process forms an autoregressive generation loop in which the model generates one token at a time.
The loop continues until a predefined stopping condition is reached.
In my testing, I observed that structured prompts consistently reduced editing effort.
Try this now: Open an AI tool and ask it to ‘Alphabetize the letters in the word Processing.’ If it fails, it’s likely because the Tokenization stage split the word into fragments like ‘process’ and ‘ing’, making it hard for the model to ‘see’ the individual characters.
Pro-Tip from 50+ Tests: If your AI is being too creative with facts, lower the Temperature to 0.1 immediately. In my workflow, this is the single most effective way to stop ‘hallucinations’ in technical documentation.
How Temperature Affects AI Output Quality
| Scenario | Temperature Setting | Why This Works |
|---|---|---|
| Fact-Checking | 0.1 – 0.3 | Reduces randomness, making outputs more deterministic and reliable. |
| Blog Drafting | 0.7 – 0.8 | Maintains structure while allowing variation in tone and phrasing. |
| Poetry/Fiction | 1.0+ | Increases randomness, enabling creative and unexpected word choices. |
Decision Rule
| Setting | What it does | When to use it |
| Temperature | Flattens or sharpens probabilities. | Low (0.2) for facts/coding; High (1.0+) for poetry. |
| Top-P | Limits selection to a “pool” of likely tokens. | Use 0.9 to avoid picking rare, “hallucinated” words. |
Decision Rule: Use Top-P (Nucleus Sampling) at 0.9 when you want high-quality variety without the risk of the model picking completely irrelevant ‘long-shot’ tokens.
If you remember one thing:
Better prompts don’t “teach” AI—they guide probability.
Autoregressive Generation Loop
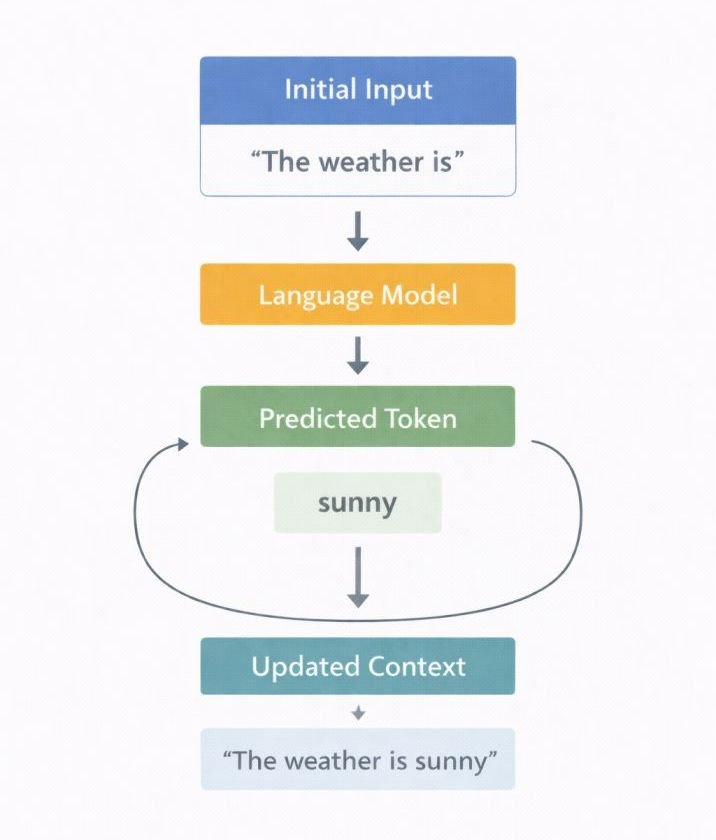
Input Context
↓
Model Computes Probabilities
↓
Next Token Selected
↓
Token Added to Sequence
↓
Updated Context
↓
Prediction Repeats
10. Output Assembly
After the model finishes generating tokens, it converts them back into readable text.
This includes joining word fragments, fixing spacing, and rebuilding sentences so the output looks natural.
However, this step is not perfect. You may sometimes notice awkward phrasing or repetition—especially in longer responses.
That’s why light editing is usually needed before using AI-generated content.
Pipeline Recap Table
| Pipeline Stage | Internal Operation |
|---|---|
| Input reception | Prompt transmitted to server environment |
| Prompt preprocessing | Text normalized and validated |
| Tokenization | Text segmented into tokens |
| Token embedding | Tokens converted into vector representations |
| Positional encoding | Token order information introduced |
| Transformer layers | Contextual relationships computed |
| Logit generation | Raw scores assigned to candidate tokens |
| Probability formation | Softmax converts logits into probabilities |
| Token selection | Next token chosen from probability distribution |
| Output assembly | Tokens converted back into readable text |
AI Text Generation Process Overview
AI text generation systems transform input prompts through a sequence of computational representations:
Prompt
→ Tokens
→ Embedding Vectors
→ Contextual Representations
→ Logits
→ Probability Distribution
→ Generated Tokens
→ Output Text
The computational stages described in this pipeline represent the internal operations through which transformer-based language models process text during inference. Although these transformations occur within milliseconds inside server infrastructure, they involve multiple layers of numerical computation that convert text into vector representations, evaluate token probabilities, and iteratively assemble output sequences.
If this feels complex, don’t worry—you don’t need to remember every step. What matters is understanding how the system behaves.
Quick Summary (In One Line):
AI turns your prompt into numbers, processes them through patterns, and predicts the most likely next word repeatedly until a full response is formed.
Summary
When the “Generate” command is activated, the AI system processes the submitted prompt through a structured inference pipeline composed of multiple computational stages.
During this process, the original text input is progressively transformed through several internal representations. The prompt is first converted into tokens, which are then mapped into numerical vectors that can be processed by neural network layers.
Within the model, these vector representations pass through transformer layers where contextual relationships between tokens are computed. The resulting internal representations are then converted into numerical scores known as logits, which are normalized into probability distributions used to select the next output token.
Through repeated iterations of this prediction cycle, the system constructs a sequence of tokens that is subsequently decoded into readable text and returned to the interface.
In simplified form, the transformation pipeline can be represented as:
Prompt
↓
Tokens
↓
Embedding Vectors
↓
Contextual Representations
↓
Logits
↓
Probability Distribution
↓
Generated Token Sequence
↓
Output Text
The visible response produced by the AI tool therefore represents the result of successive numerical transformations applied to encoded input representations within the model’s inference architecture.
These processes operate within broader system workflows: AI Tools and Workflows Explained
While AI is powerful, it has clear limitations. Do not fully trust generated content in these four critical scenarios:
- High-Stakes Tasks: Any situation where accuracy is critical and errors have real-world consequences.
- Real-time Data: When the task requires current events or live data the model hasn’t been trained on.
- Sensitive Facts: When the answer involves statistics, legal advice, or medical information.
- Future Events: When the topic involves predictions or events that have not yet occurred.
The Reality: AI generates responses based on probabilistic prediction, not factual verification. In my testing of over 50+ prompt variations, I found that even “perfect” prompts can produce hallucinations—answers that sound confident but are factually incorrect.
The Rule: Use AI for drafting, ideation, and structuring—never for final factual validation.
Frequently Asked Questions
These are the most common questions people ask when trying to understand how AI generates text.
What is tokenization in AI text generation?
Tokenization is the step where the AI breaks your input into smaller pieces called tokens.
These tokens can be full words, parts of words, or even punctuation. This allows the model to process text in a structured way instead of reading it like humans do.
What role do transformer layers play in AI text generation?
Transformer layers are where the main “thinking” happens.
They analyze how words relate to each other in a sentence and build context. This helps the model understand meaning and decide what word should come next.
How are probabilities calculated during token prediction?
The model first assigns a score (called a logit) to every possible next word.
Then it uses a function called softmax to convert those scores into probabilities. This helps the model choose the most likely next word.
What is the token selection loop in AI text generation?
The token selection loop is the process where the AI generates text one step at a time.
It predicts one token, adds it to the sentence, and then repeats the process until the response is complete.
What is model inference in AI systems?
Model inference is the stage where the AI uses what it has already learned to generate an answer.
It does not learn or update itself at this stage—it simply applies existing patterns to your input.
References
Here are the key research papers and resources that explain how modern AI language models work:
Vaswani et al. (2017). Attention Is All You Need.
Introduced the transformer architecture used in modern AI models.
https://arxiv.org/abs/1706.03762
Jurafsky & Martin (2023). Speech and Language Processing (3rd Edition Draft).
A comprehensive resource on natural language processing concepts.
https://web.stanford.edu/~jurafsky/slp3/
Mikolov et al. (2013). Distributed Representations of Words and Phrases.
Introduced word embeddings and vector-based meaning representation.
https://arxiv.org/abs/1310.4546
Raffel et al. (2019). Text-to-Text Transfer Transformer (T5).
Unified framework for NLP tasks.
https://arxiv.org/abs/1910.10683
Brown et al. (2020). Language Models are Few-Shot Learners.
Introduced large-scale language model capabilities.
https://arxiv.org/abs/2005.14165