

Introduction
Why AI tools misinterpret prompts is closely related to how statistical language models process token sequences, construct contextual representations, and generate outputs through probability-based predictions. AI tools that generate text or perform automated analysis process prompts using statistical language models trained on large datasets. This article explains conceptual mechanisms in statistical language models that can influence how prompts are interpreted during automated response generation.
These systems interpret prompts by converting textual input into token sequences, constructing contextual representations, and estimating probability distributions for potential outputs.
Although this computational process allows AI systems to generate coherent responses, the interpretation of prompts is not equivalent to human understanding. Instead, the system evaluates statistical relationships between tokens learned during training. Because of this statistical foundation, AI tools may sometimes interpret prompts differently from what a user intends.
The mechanisms through which AI systems interpret prompts—including tokenization, contextual representation, probability estimation, and sequential token generation—are examined in How AI Tools Interpret Prompts, which explains how language models process input text during inference.
Misinterpretation occurs when the contextual representation constructed by the model differs from the intended meaning of the prompt. This article examines the structural reasons why such discrepancies may arise during prompt interpretation in modern AI systems.
This discussion focuses specifically on semantic ambiguity and statistical interpretation in language models, which differs from structural representation constraints where parts of prompts may receive reduced representation during processing.
Misinterpretation in Statistical Language Models
AI tools commonly rely on language models that generate responses by predicting sequences of tokens based on learned statistical patterns. During inference, the model evaluates the prompt and estimates the likelihood of possible output tokens using probability distributions derived from contextual representations.
Because these systems rely on statistical relationships rather than direct semantic reasoning, the interpretation of a prompt depends on patterns observed in training data. When the statistical associations identified by the model differ from the user’s intended meaning, the generated response may appear to misinterpret the prompt.
Misinterpretation therefore reflects the interaction between the prompt structure, the statistical patterns encoded within the model, and the probabilistic mechanisms used to generate outputs.
Ambiguity in Token Sequences
Multiple Interpretations of the Same Tokens
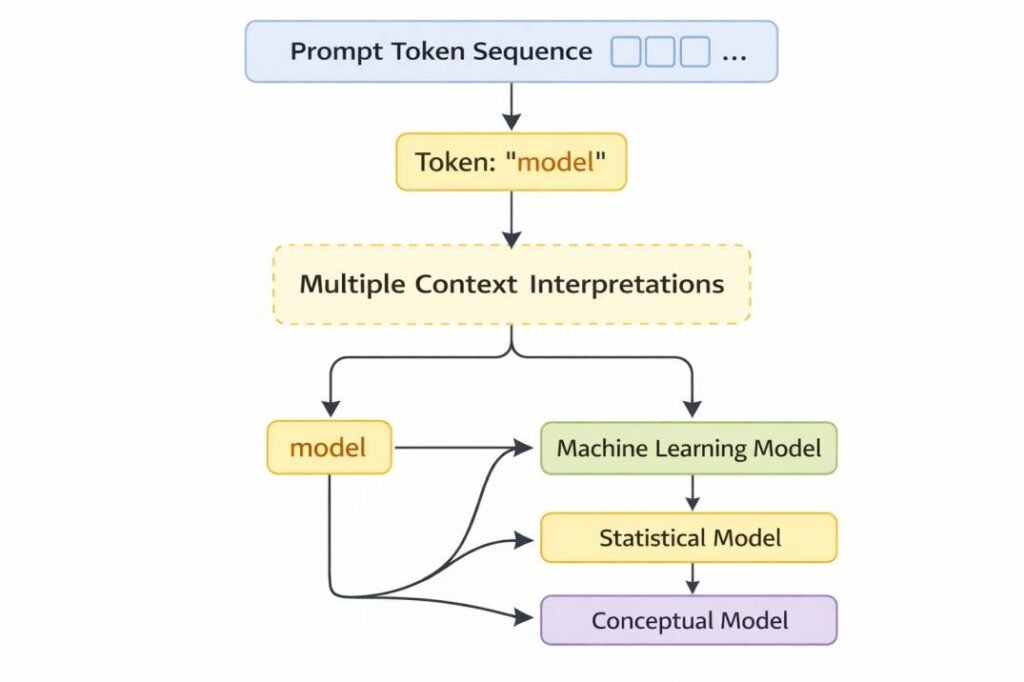
Language models process prompts as sequences of tokens rather than as complete semantic structures. Individual tokens may possess multiple potential meanings depending on the surrounding context.
For example, a token such as “model” may refer to:
- a machine learning system
- a statistical framework
- a conceptual representation
Because tokens are interpreted relative to neighboring tokens within the sequence, ambiguous terms may produce multiple plausible contextual representations.
Influence of Token Context
When the surrounding tokens provide limited contextual information, the model may construct a contextual representation that differs from the user’s intended meaning. In such cases, the response generated by the system reflects the statistical interpretation derived from the token sequence rather than a definitive semantic interpretation.
Ambiguity within token sequences therefore represents one of the primary factors that can lead to prompt misinterpretation.
This mechanism operates in conjunction with probabilistic evaluation and token interaction patterns, contributing to variation in prompt interpretation.
Contextual Representation Limitations
Context Construction in Language Models
After tokenization and embedding, prompts are processed through computational layers that construct contextual relationships between tokens. These relationships form internal vector representations that encode how tokens influence one another within the sequence.
The contextual representation generated by the model provides the computational basis for predicting subsequent tokens.
This mechanism operates in conjunction with context construction and attention weighting, influencing how token relationships are formed.
Differences Between Statistical Context and Intended Meaning
Although contextual representations capture relationships between tokens, they do not represent explicit semantic understanding. Instead, they reflect patterns observed in training data.
If the contextual relationships identified by the model emphasize associations that differ from the user’s intended interpretation, the resulting probability distribution for candidate tokens may lead to an unexpected response.
Misinterpretation may therefore arise when the contextual representation constructed by the model does not align with the conceptual meaning intended by the user.
Influence of Training Data Patterns
Statistical Learning from Large Datasets
Language models are trained on large collections of text that contain patterns of word usage across many contexts. During training, the model learns statistical relationships between tokens based on how frequently they appear together.
These learned patterns influence how the model interprets prompts during inference.
Dominant Patterns in Training Data
If certain token relationships appear frequently in the training data, the model may prioritize those patterns when constructing contextual representations.
For example, if particular phrases commonly appear together in the training data, the model may associate them even when a user intends a different interpretation. As a result, the generated response may reflect the dominant statistical pattern rather than the intended meaning of the prompt.
This mechanism operates in conjunction with statistical pattern learning and contextual representation, contributing to variation in interpretation outcomes.
Probability-Based Output Selection

Logits and Candidate Tokens
Once contextual representations are constructed, the model computes numerical scores for candidate tokens in its vocabulary. These scores, commonly referred to as logits, represent the model’s internal evaluation of how compatible each token is with the interpreted prompt context.
Probability Distributions and Token Selection
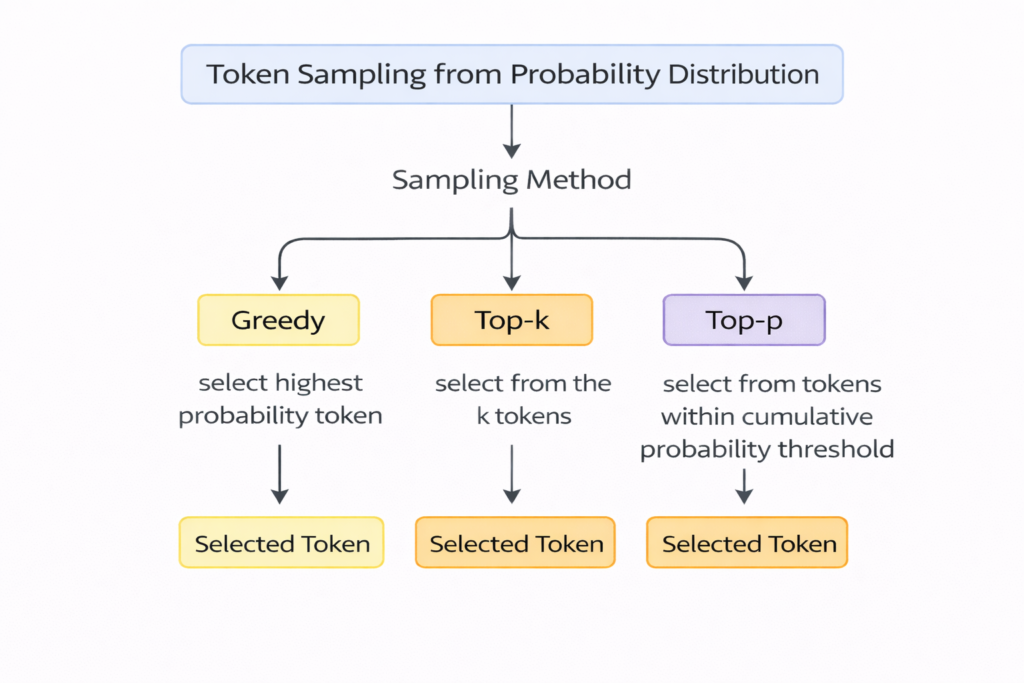
Logit scores are converted into probability values that form a distribution across candidate tokens. Tokens with higher probability values represent statistically stronger continuations of the interpreted prompt.
Because multiple tokens may possess similar probability values, the token selected during generation may vary depending on the sampling method used by the system.
This probabilistic mechanism means that the generated response reflects the most statistically plausible continuation rather than a definitive interpretation of the prompt.
This probabilistic mechanism is also associated with why AI tools may generate different outputs for the same input: Why AI Tools Give Different Answers
This mechanism operates in conjunction with contextual representation and sampling strategies, contributing to variability in output generation.
Prompt Structure Sensitivity
Influence of Wording and Token Order
The structure of a prompt can influence how contextual relationships between tokens are constructed. Variations in wording, sentence structure, or token order may produce different contextual representations within the model.
Even small changes in phrasing can alter how tokens relate to one another in the sequence.
Example of Structural Variation
Consider the prompts:
- “Explain how AI tools interpret prompts.”
- “Describe how prompts are interpreted by AI tools.”
Although both prompts describe the same topic, the arrangement of tokens differs. These structural differences may produce slightly different contextual representations, which in turn may influence the probability distributions used during token prediction.
As a result, the generated responses may vary even when the prompts address the same concept.
This structural sensitivity is also related to how certain parts of prompts may receive reduced representation during processing: Why AI Tools Sometimes Ignore Parts of a Prompt
This mechanism operates in conjunction with token interaction patterns and contextual constraints, contributing to variation in interpretation outcomes.
Conceptual Example of Prompt Misinterpretation
Example Prompt
Consider the prompt:
“Explain the model used in AI systems.”
The token “model” may refer to different concepts depending on the context, such as:
- a machine learning model
- a conceptual framework
- a statistical representation
Multiple Possible Interpretations
Because the prompt contains limited contextual detail, the language model may construct different contextual representations depending on the statistical relationships learned during training.
For example, the generated response might interpret “model” as referring to machine learning architecture, while the user may have intended a discussion of statistical modeling methods.
This example illustrates how token ambiguity and contextual representation influence the interpretation of prompts.
This mechanism operates in conjunction with prompt design characteristics and probabilistic evaluation, influencing how interpretation differences emerge in AI systems.
Relationship Between Prompt Design and System Behavior
The interpretation of prompts by AI systems depends on how tokens interact within the sequence provided by the user. Prompts that contain ambiguous terminology or limited contextual detail may produce contextual representations that differ from the user’s intended meaning.
Because language models operate through statistical prediction mechanisms, variations in prompt wording can influence the probability distributions used during token generation.
The interaction between prompt structure, contextual representation, and probabilistic token selection therefore contributes to the variability observed in AI-generated responses.
Summary
AI tools may misinterpret prompts due to the statistical mechanisms used by language models during inference. Prompts are processed as token sequences that are converted into contextual representations and used to estimate probability distributions over candidate tokens.
Misinterpretation may arise when the contextual relationships constructed by the model differ from the intended meaning of the prompt. Factors that contribute to this behavior include ambiguity in token sequences, dominant patterns in training data, probabilistic token selection, and sensitivity to prompt structure.
These mechanisms reflect the statistical nature of language model processing rather than errors in a traditional rule-based interpretation system. Understanding how tokenization, contextual representation, and probability distributions influence prompt interpretation helps explain why AI tools may produce responses that appear to misinterpret user instructions.
Relationship Between Prompt Interpretation and AI Generation Processes
Prompt interpretation occurs during the inference stage of language model operation. When a user submits a prompt, the input text is first converted into token sequences and embedding representations. These representations are then processed through transformer layers that construct contextual relationships between tokens.
During this stage, the model forms a contextual representation of the prompt. If the token sequence contains ambiguous wording, incomplete context, or structural variation, the contextual representation produced by the model may differ from the meaning intended by the user.
The contextual representation then influences the probability distributions calculated during token prediction. Because the model generates output by selecting tokens from these probability distributions, differences in contextual representation can lead to different interpretations of the same prompt and therefore different generated responses.
This relationship connects prompt misinterpretation to other mechanisms involved in AI text generation, including token prediction, sampling strategies, and sequential response generation.
Related Articles
This topic is also related to the following structural discussions:
- Why AI Tools Give Different Answers
- How AI Tools Work: Architecture and Generation Process
- How AI Tools Interpret Prompts
Reference Sources
The conceptual explanations in this article correspond with mechanisms described in research literature on probabilistic language models, transformer architectures, and text generation systems. The following academic sources document the computational structures discussed throughout the article.
Transformer Architecture
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017).
Attention Is All You Need.
https://arxiv.org/abs/1706.03762
This research introduced the transformer architecture, which uses self-attention mechanisms to model contextual relationships between tokens in a sequence.
Neural Probabilistic Language Models
Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003).
A Neural Probabilistic Language Model.
Journal of Machine Learning Research.
https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
This study describes probabilistic approaches to language modeling that estimate the likelihood of token sequences.
Generative Language Models
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019).
Language Models are Unsupervised Multitask Learners.
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
This research examines large-scale generative language models and their ability to learn patterns from large datasets.
Large Language Models and Few-Shot Learning
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., … Amodei, D. (2020).
Language Models are Few-Shot Learners.
https://arxiv.org/abs/2005.14165
This paper explores the capabilities of large language models and explains how prompts influence task performance.
Computational Linguistics Foundations
Jurafsky, D., & Martin, J. H.
Speech and Language Processing (3rd Edition Draft).
https://web.stanford.edu/~jurafsky/slp3/
This textbook provides a comprehensive overview of natural language processing, language modeling, and computational linguistics.
Token Sampling and Generation Methods
Holtzman, A., Buys, J., Du, L., Forbes, M., & Choi, Y. (2020).
The Curious Case of Neural Text Degeneration.
https://arxiv.org/abs/1904.09751
This research analyzes sampling methods such as top-k and nucleus (top-p) sampling used in neural text generation.
- Top 10 Free AI Tools for Beginners (2026 Guide) - April 3, 2026
- How to Use ChatGPT for Beginners (Step-by-Step Guide) - March 31, 2026
- Why AI Tools Fail Outside Training Conditions - March 29, 2026