
Quick Answer
AI tools fail because they generate outputs from learned patterns rather than true understanding. Small changes in prompts, missing context, evolving real-world conditions, and unverified information can reduce accuracy without obvious warning signs. Monitoring and human review help identify these failures before they affect decisions.
What you’ll learn:
✓ Why AI answers change unexpectedly
✓ The hardest AI failure to detect
✓ Why monitoring matters after deployment
✓ When AI should not be trusted
Quick Reference Table
| Cause | Common result |
|---|---|
| Limited training scope | Struggles with new situations |
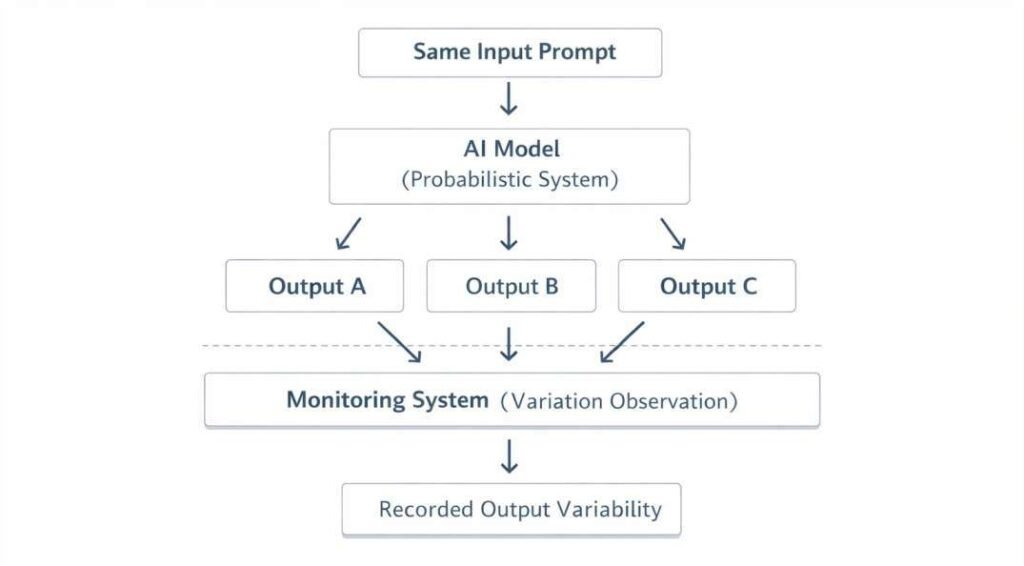
| Probabilistic outputs | Different answers for similar prompts |
| Context sensitivity | Small wording changes alter results |
| Missing verification | Confident but incorrect responses |
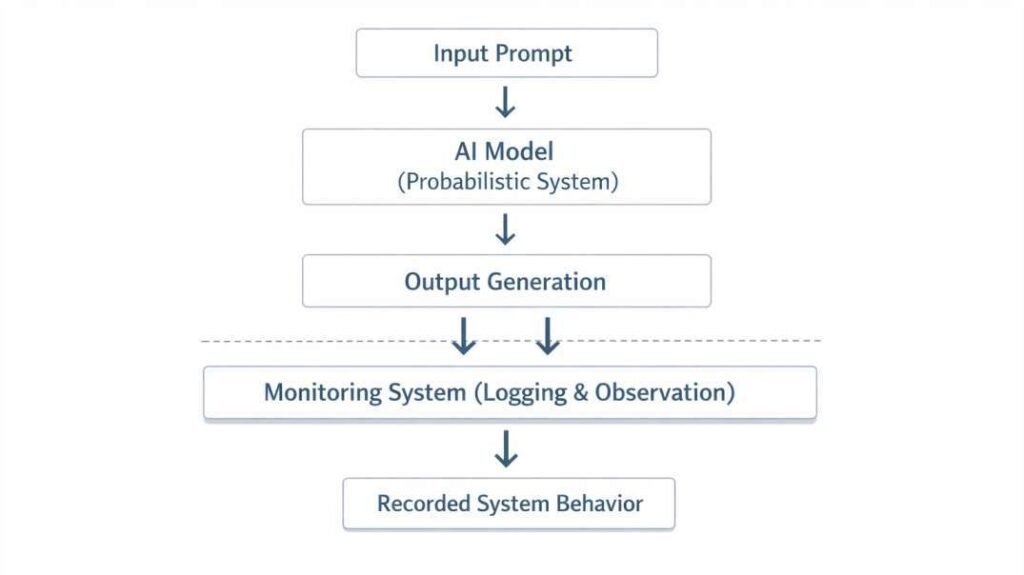
The Core Problem: Probability, Not Understanding
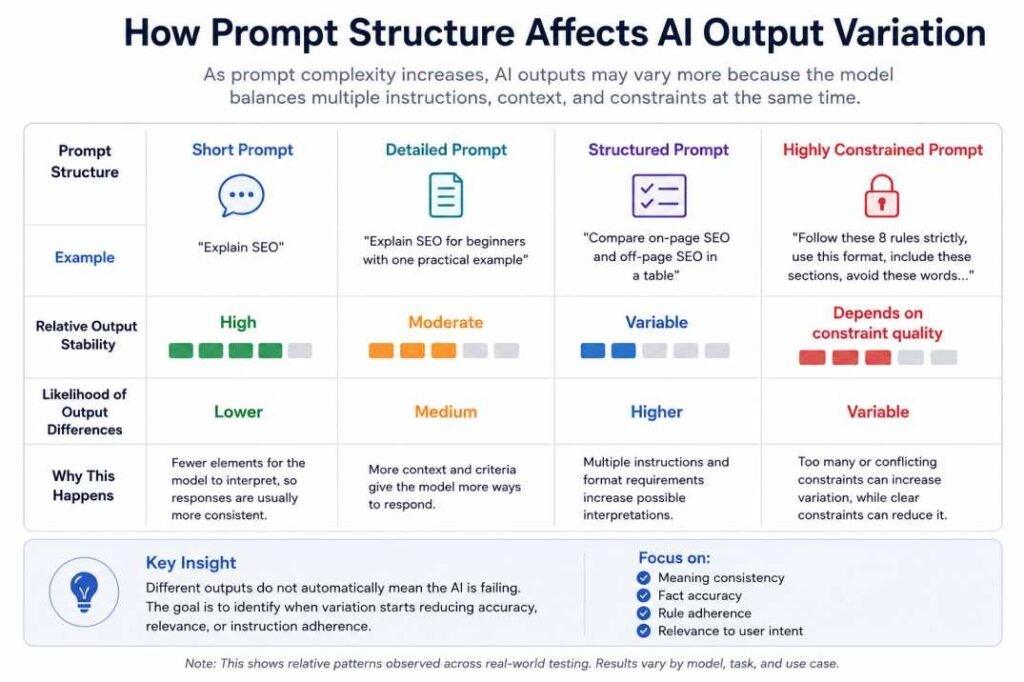
AI tools do not retrieve truth from a database. They generate responses by predicting patterns from training data, which is why fluent answers can still contain mistakes. To see how prompt design changes AI behavior, read How Prompt Structure Controls AI Output (The Logic Test).
Additional Factors That Influence AI Errors
- LLM hallucinations: models can generate plausible but incorrect details.
- Tokenization limits: long inputs can reduce retention of important instructions.
- RLHF (Reinforcement Learning from Human Feedback): behavior tuning can sometimes prioritize helpfulness over precision.
- Data contamination: low-quality or biased training data can affect outputs.
Three Failure Modes That Don’t Look Like Failures
The most dangerous AI failures produce confident, plausible-looking output. Users rate them as correct and move on.
Silent drift in deployed systems
A chatbot or recommendation engine performs well at launch. Over months, user query patterns evolve beyond the training distribution — new phrasing, new topics, shifting context. The system keeps answering, but answers increasingly miss the mark. Because there’s no error message, no one investigates.
Illustrative scenario: A recommendation system reviewed after months of unmonitored use may begin showing reduced diversity and repeated recommendation patterns as user behavior shifts.
Stale fraud/policy detection
Models trained on historical fraud patterns cannot detect novel attack vectors. False negatives accumulate silently. The system reports healthy metrics (low false positives) while missing an entire class of new threats.
Confident but incomplete answers
Confident but incomplete answers are often difficult to detect because they appear grammatically correct and relevant while quietly missing important context, assumptions, or edge cases. Since the response still sounds convincing, users often accept it without noticing what was omitted. This behavior closely relates to Hallucination of Authority: When AI Sounds Right but Is Wrong (Case Study + Prevention Guide).
This failure becomes more common in long or highly constrained prompts where models may satisfy some instructions while silently dropping others. Learn why this happens in Why Multi-Step Prompts Fail (And How to Fix Them).
Unexpected Observation
During repeated use, obvious mistakes were usually easy to spot. More difficult problems came from answers that sounded complete but quietly ignored one important detail. Because the response still appeared polished and confident, these failures were easy to trust.
Practical finding: Obvious AI mistakes were usually easy to catch. The harder failures came from responses that sounded complete but quietly omitted one important detail. These failures often escaped attention because the wording remained confident and polished.
Agentic AI: A Different Failure Class
Standard chatbot failures are output errors. Agentic AI — systems that plan, execute multi-step tasks, and call external tools — introduces execution errors that compound without visibility. Teams managing repeated AI processes often move toward AI Workflows for Teams: Moving Beyond One-Off Prompts.
Agentic drift: An agent assigned “generate a research report” may misalign on intermediate sub-goals over many steps, producing an artifact that superficially resembles a report but serves a different purpose than requested.
Multi-agent conflict: When agents A, B, and C collaborate in a chain, agent C may reverse or override agent A’s output without any single agent recognizing the loop. Result: infinite iteration with no progress and no error signal.
Traditional output monitoring doesn’t catch these. Agentic systems require:
- Task-level monitoring (not just output monitoring)
- Decision-chain logging
- Hard execution boundaries and human override triggers
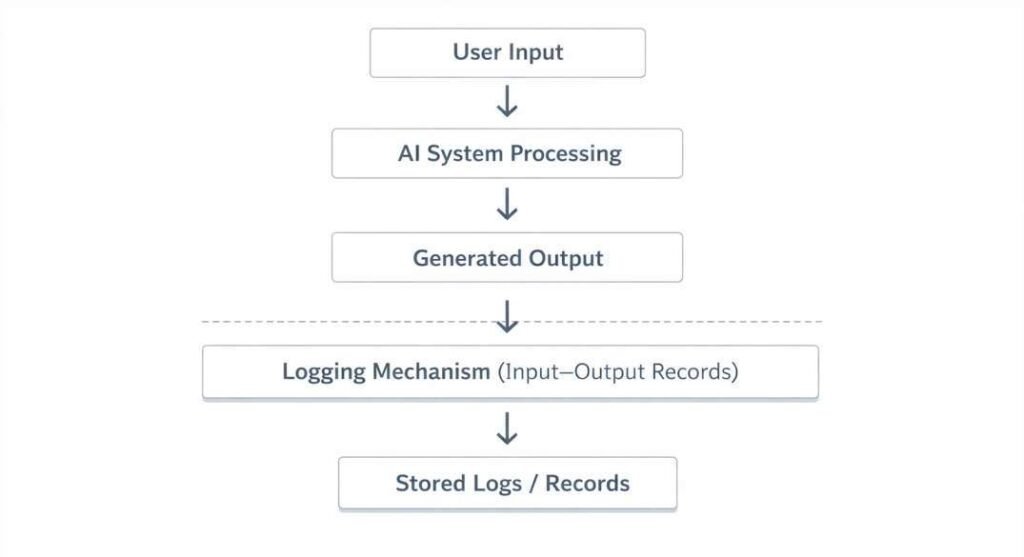
A Practical Monitoring Framework
Monitoring doesn’t make AI smarter. It makes the system’s degradation visible before it becomes expensive.
Step 1: Define “good” quantitatively before deployment
Set explicit thresholds against which you’ll measure:
- Response relevance ≥ X%
- Critical error rate ≤ Y%
- Output diversity metric ≥ Z (for recommendation systems)
Step 2: Track input distribution, not just output quality
If user query patterns shift, performance metrics may look stable while actual relevance collapses. Log both what users are asking and what the system returns.
Step 3: Benchmark against a fixed evaluation set monthly
Compare current performance on a held-out set of representative queries against the baseline. Don’t rely solely on production feedback — users don’t report what they don’t notice.
Step 4: Set automated alerts for threshold breaches
Define which metrics trigger investigation (sudden accuracy drop, spike in repeated outputs, anomalous response length distribution) and route alerts to someone with authority to act.
Step 5: Retrain or adjust based on evidence, not schedule
Updates should be triggered by detected distribution shift or performance degradation — not quarterly on a fixed calendar.
Monitoring Limitations
Monitoring helps identify unusual behavior, performance changes, and hidden failure patterns, but it cannot remove the core limitations built into AI systems.
Monitoring cannot:
- Remove probabilistic variation from outputs
- Guarantee factual accuracy
- Improve understanding of unfamiliar situations
- Eliminate the need for human review
When to Avoid AI Entirely
Avoid relying on AI when:
- Decisions involve legal, financial, or health consequences and cannot be reviewed
- Real-time information is required
- Outputs cannot be independently verified before action is taken
2026 Failure Pattern Reference
| Failure type | Hidden signal | What to check | Action |
|---|---|---|---|
| Confident but incomplete output | Sounds correct but misses important details | Missing constraints or assumptions | Verify important details |
| Model drift | Relevance slowly declines | Compare with benchmark examples | Re-test performance |
| Repetition bias | Similar outputs repeatedly appear | Reduced diversity | Review recommendation logic |
| Agentic loop | Actions repeat without progress | Task repetition | Add limits and human oversight |
| Input sensitivity | Small prompt changes create large output differences | Compare prompt variations | Standardize prompt structure |
Standards Alignment
This framework maps to the NIST AI Risk Management Framework (AI RMF), including the 2026 Critical Infrastructure profiles:
- Govern — Define who owns monitoring and who can act on alerts
- Map — Identify every AI touchpoint and workflow where AI systems are used
- Measure — Track performance and risk metrics against pre-defined thresholds
- Manage — Retrain, restrict, or retire systems based on measured evidence
Full framework: nist.gov/itl/ai-risk-management-framework
Related Reading
- Why AI Gives Wrong Answers: A Practical Testing Analysis
- Why AI Tools Behave Unpredictably Compared to Traditional Software
- What Happens After Clicking “Generate”? Inside the AI Text Generation Process
Bottom Line
AI tools rarely fail through obvious crashes or error messages. More often, failures appear as small declines in relevance, accuracy, or consistency that accumulate over time. Monitoring helps make these hidden changes visible before they affect decisions, users, or business outcomes.
AI should be treated as a support tool with managed reliability — not a source of truth with assumed accuracy.
Frequently Asked Questions
Q: Why do AI tools sometimes give different answers to the same question?
A: AI systems generate responses probabilistically, which means multiple valid outputs can exist for similar inputs. Small wording or context changes can influence the final response.
Q: What is the most difficult AI failure to detect?
A: Confident but incomplete answers are often difficult to detect because they appear correct while quietly missing important context or constraints.
Q: Can AI failures be completely prevented?
A: No. AI systems always have limitations. Monitoring, human review, and verification reduce risk but cannot remove failures entirely.
Q: Does monitoring make AI more accurate?
A: Monitoring does not improve how a model generates outputs. It helps identify unusual behavior, performance changes, and hidden errors over time.
Q: When should AI not be used?
A: Avoid relying on AI when decisions involve legal, financial, medical, or other high-risk situations where outputs cannot be independently verified.
References
- NIST AI Risk Management Framework (AI RMF) — Guidance on AI risk identification, governance, monitoring, and lifecycle management.
- OECD AI Classification Framework — Framework for categorizing AI systems and understanding operational risks.
- European Commission Ethics Guidelines for Trustworthy AI — Principles for transparency, accountability, and trustworthy AI systems.
- Google Responsible AI Practices — Guidance on evaluating and deploying AI responsibly.
- Microsoft Responsible AI Standard — Governance and monitoring practices for AI systems.
- Stanford AI Index Report — Data and research on AI trends, capabilities, and limitations.
- IBM AI Governance Resources — Information on monitoring, governance, and AI system oversight.
- Attention Is All You Need (Transformer Paper) — Foundational research introducing the transformer architecture used in modern AI systems.
Last update on May 2026.

Independent AI Behavior Researcher
Soumen Chakraborty is the founder of AI Tools Usage Guide and an independent AI Behavior Researcher. His research examines how AI systems behave in practical workflows, with a focus on instruction-following failures, prompt reliability, hallucination risks, context loss, and output reliability.