
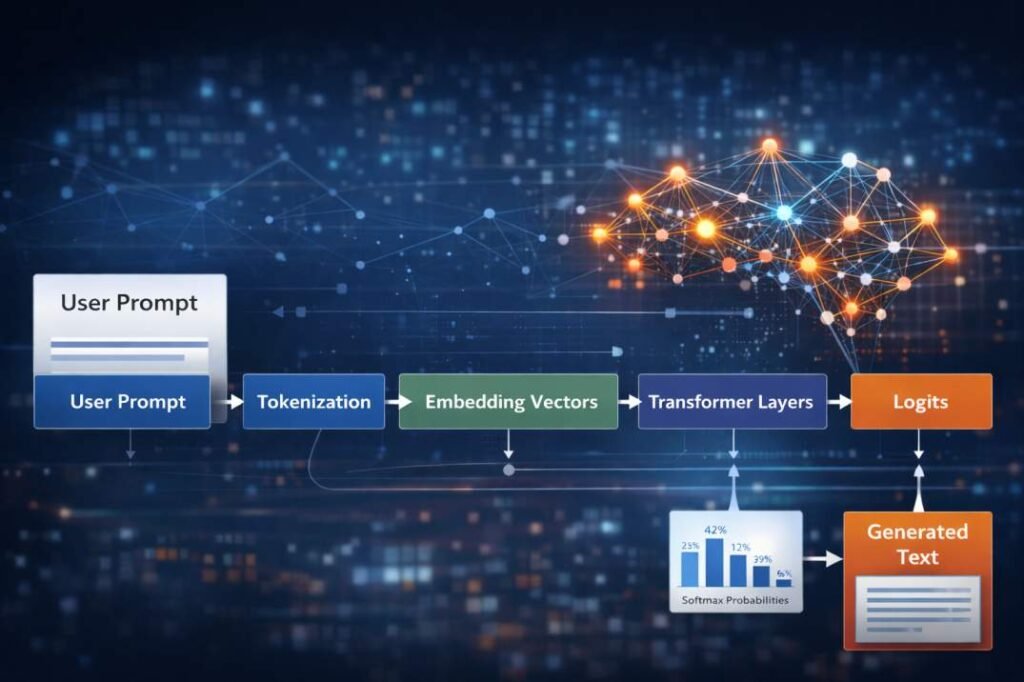
Introduction
Have you ever asked AI the same question twice and received different answers?
Or wondered why AI sounds confident even when it is wrong?
The answer starts with what happens after clicking “Generate.”
AI does not create responses by understanding meaning like humans do. It generates text by predicting likely word sequences from learned patterns.
Understanding that process helps explain why AI behaves the way it does and how to use it more effectively.
Quick Answer
When you click “Generate,” an AI model:
- Receives your prompt
- Converts text into tokens
- Converts tokens into numerical vectors
- Processes relationships through transformer layers
- Calculates probabilities
- Selects the next token
- Repeats until the response ends
The entire process usually happens within milliseconds.
Why this matters practically
When you understand how AI generates text, many confusing behaviors become easier to explain.
Understanding the process makes several common AI behaviors easier to explain.
What Is AI Text Generation?
AI text generation is the process by which an AI model predicts and produces text one token at a time based on patterns learned during training. Rather than retrieving sentences from a database, the model repeatedly estimates the most likely next token until it completes a response.
This process happens during inference and is influenced by your prompt, the available context, and generation settings such as temperature and Top-P.
Prompt Quality: A Real Example
Prompt A:
Explain machine learning.
Typical output:
A broad explanation with generic definitions.
Prompt B:
Explain machine learning to a restaurant owner using three examples.
Typical output:
Examples involving customer behavior, demand forecasting, and inventory planning.
Why the difference?
The second prompt gives the model clearer constraints and reduces ambiguity.
Table of Contents
Key Terms Used in This Guide
Token
A text fragment — a word, part of a word, or punctuation mark — that the model processes as a discrete unit. “Processing” might become two tokens: process + ing.
Embedding Vector
A list of numbers representing a token’s meaning, derived from patterns in training data. Tokens used in similar contexts produce numerically similar vectors.
Transformer Layer
A neural network layer that computes how each token relates to every other token in the sequence. Multiple stacked layers progressively refine this understanding.
Logits
Raw, unnormalized scores assigned to every token in the model’s vocabulary as candidates for the next position. Higher score = stronger model preference.
Softmax
A mathematical function that converts logit scores into probabilities that sum to exactly 1.0 across all vocabulary tokens.
Where This Process Occurs in an AI System
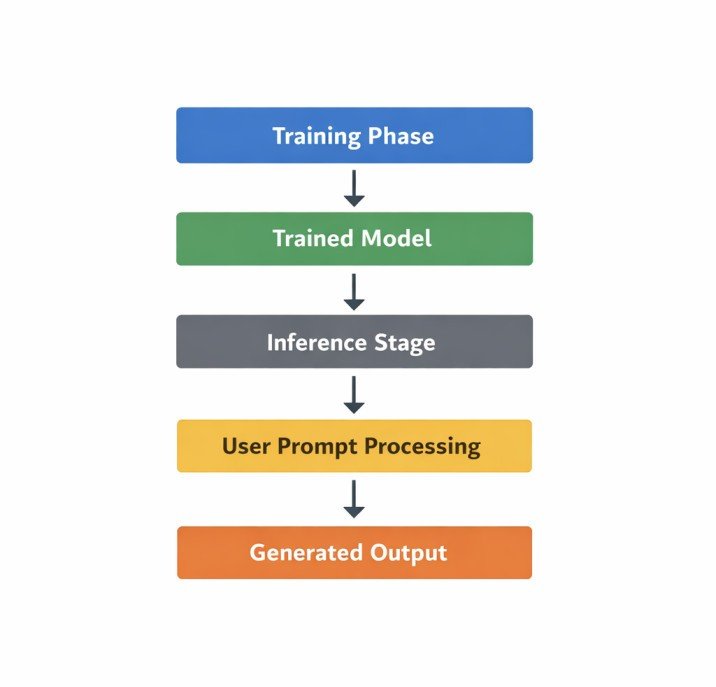
AI text generation happens during a stage called inference — the phase where a trained model takes your prompt and generates a response. At this stage, the underlying model weights are not updated during inference, although external systems may provide fresh context through tools, retrieval, or memory layers. The model applies patterns learned during training to generate text during inference.
This distinction matters: the core model cannot learn from your conversation. Retrieval-augmented systems and tool-enabled models can access live data, but the base generation mechanism described in this pipeline applies to all of them. This is why providing context inside your prompt remains important regardless of which interface you use.
AI Text Generation Process: Inference Pipeline
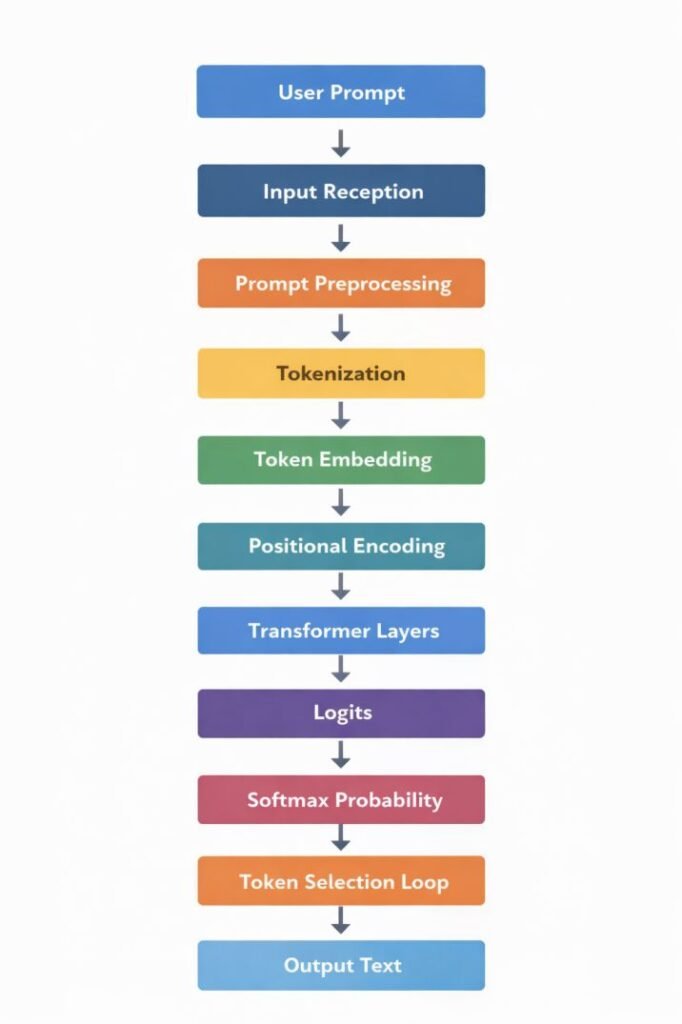
User Prompt
↓
Input Reception
↓
Prompt Preprocessing
↓
Tokenization
↓
Token Embedding
↓
Positional Encoding
↓
Transformer Processing Layers
↓
Logit Generation
↓
Probability Distribution (Softmax)
↓
Token Selection Loop
↓
Output Text
Input Reception
When you click “Generate,” your prompt is transmitted to the AI server over HTTPS. The system validates the request — checking authentication, payload size, and rate limits — before routing it to a model inference worker. Under normal load conditions this handoff completes very quickly, though latency varies by provider infrastructure and request queue depth.
This step has no bearing on output quality. It’s infrastructure. Output quality begins in the next step.
Prompt Preprocessing
Before the model can process your text, the system normalizes it. AI models don’t operate on raw characters — they need clean, consistently encoded input that the tokenizer can handle without errors.
During preprocessing the system typically: fixes character encoding issues, strips unsupported Unicode ranges, checks input length against the model’s context window, and formats system-level instruction prefixes if the API is being called with a system prompt.
Context window truncation
If your prompt exceeds the model’s maximum token limit, the system truncates it — usually from the beginning or the middle. This is a common and silent cause of degraded outputs on long documents. If an AI seems to “forget” context from earlier in a long input, truncation is often the cause.
Tokenization
After preprocessing, the system breaks your input into smaller pieces called tokens.
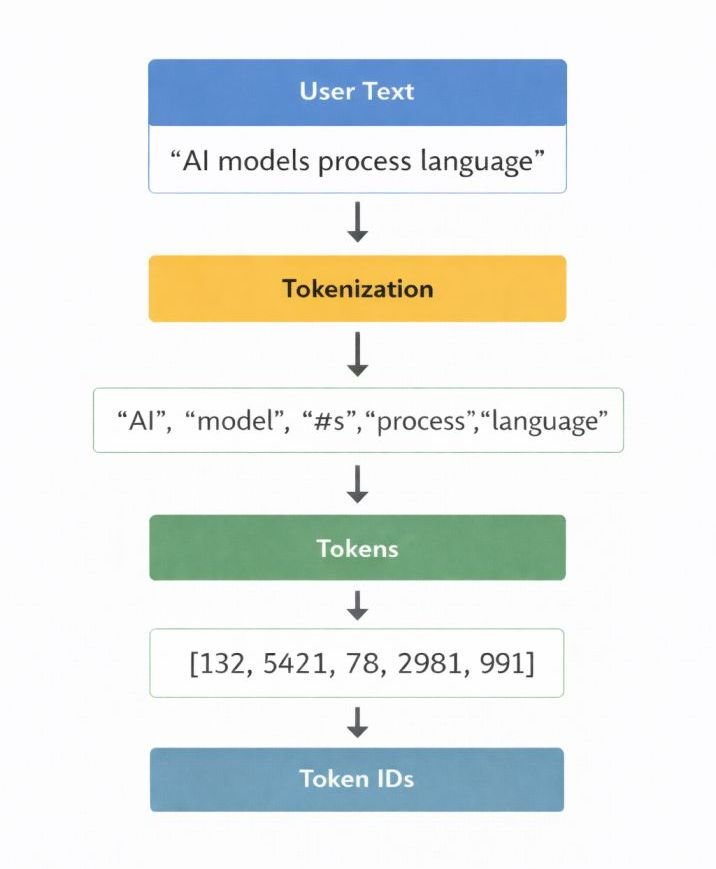
Tokenization converts your text into discrete units the model can process mathematically. Most modern models use a method called Byte-Pair Encoding (BPE), which splits text into frequently occurring sub-word fragments rather than whole words. Common words become single tokens; rare or compound words get split.
For example, the word processing may tokenize as process + ing. The word Strawberry commonly tokenizes as Straw + berry — two tokens with no visible boundary at the letter level.
Why AI fails at letter-counting tasks
Ask an AI to count the letter “r” in “Strawberry” and it will often answer incorrectly (there are 3). This is a direct consequence of tokenization. The model never “sees” the individual characters
S,t,r,a,w,b,e,r,r,yas a sequence. It sees two tokens:Strawandberry. When asked to count letters, the model must infer character composition from those tokens probabilistically — and it does so with poor accuracy. This is not a reasoning failure; it is an architectural one.
Try this yourself: Open any AI tool and ask it to “Alphabetize the letters in the word Processing.” If it fails, it’s because tokenization has split the word before the model can reason about individual characters. Compare with a short, common word like “cat” — the model handles those more reliably because they tokenize as a single unit.
Key takeaway
AI processes token fragments rather than individual characters.
This explains why spelling, counting letters, and character-level tasks can fail even when broader language tasks succeed.
Token Embedding
Each token ID is mapped to a high-dimensional numerical vector. The exact dimensionality varies significantly between model architectures — smaller models use fewer dimensions, larger ones considerably more. These vectors are learned during training and encode semantic relationships: tokens that appear in similar linguistic contexts end up with numerically similar vectors.
For example, the vectors for SEO and marketing will be more similar to each other than either is to photosynthesis, because they appear near similar words in the training corpus.
At this point, your prompt exists entirely as a matrix of floating-point numbers. No text remains. This numerical form is what the model’s mathematical operations actually process.
Embeddings don’t encode word order
A critical limitation: at this stage, the vectors contain no information about where each token appeared in your prompt. “AI improves SEO” and “SEO improves AI” would produce the same embedding vectors for each word. Order is handled in the next step.
Positional Encoding
Transformer models process tokens simultaneously rather than one-by-one.
The system therefore needs a mechanism for understanding relationships.
The core mechanism is self-attention.
For each token the model effectively asks:
“Which other tokens matter most right now?”
The system assigns:
- higher attention → more relevant tokens
- lower attention → less relevant tokens
Try this: Give an AI a numbered list of 10 items and ask it to “swap item 3 and item 8.” The quality of its response reveals how well the model is tracking positional information in your specific context.
Key takeaway
Meaning is not determined only by words.
Position information helps the model distinguish who did what and in what order.
Why You Should Care About This
You do not need to understand every technical detail.
Three practical things matter:
- Small prompt changes can create different outputs
- Long prompts can weaken instructions
- AI can sound confident while still being wrong
Transformer Layers: How a Neural Network Completes Your Text
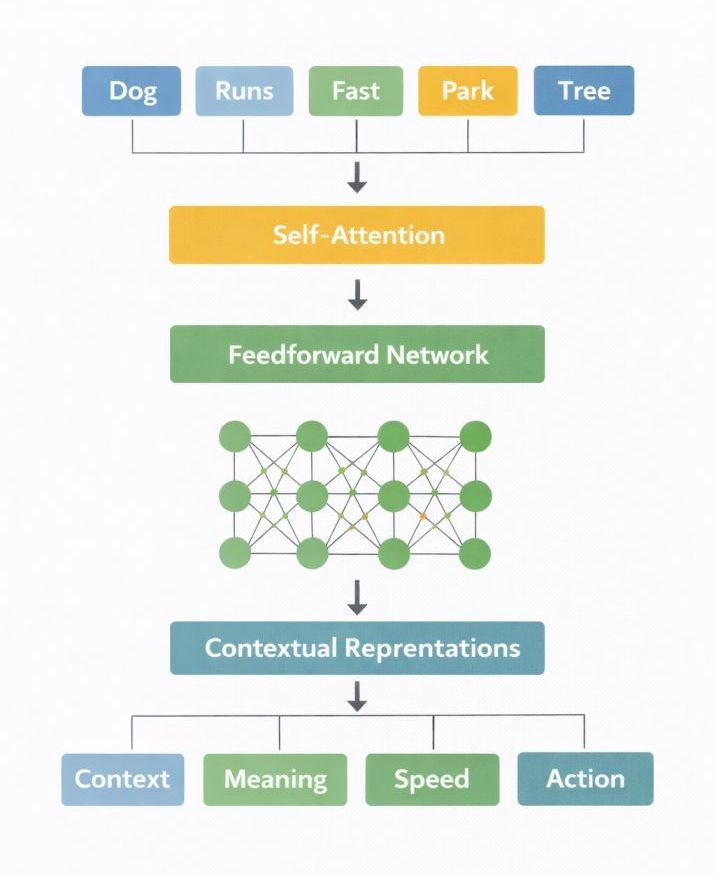
The transformer layers are where the substantive computation happens. A large language model may have 32 to 96 or more transformer layers stacked sequentially. Each layer refines the token representations by computing relationships between every token and every other token in the sequence.
The core mechanism is called self-attention. For each token, the attention mechanism asks: “Which other tokens in this sequence are most relevant to predicting what comes next?” It assigns attention weights — higher weights to contextually related tokens, lower to irrelevant ones — and uses these to update each token’s representation.
After several layers, a token like “bank” will have a very different internal representation in the sentence “the river bank flooded” versus “the bank approved my loan” — even though the input token was identical. Context is encoded into the representation through the attention mechanism across layers.
Each transformer layer also contains a feedforward network that applies learned transformations to the attention output, allowing the model to perform more complex pattern matching beyond pairwise token relationships.
Logit Generation
After the final transformer layer produces its output, a single linear transformation projects that representation onto the model’s entire vocabulary — which may contain 32,000 to 100,000+ tokens depending on the model.
The result is a vector of logits: one raw score per vocabulary token. A high logit for a token means the model assigns it a strong preference as the next token. These values are real numbers that can be negative, zero, or positive — they are not yet probabilities.
Think of this as the model ranking every word in its vocabulary simultaneously based on the full context of your prompt.
Practical application: Logit Bias
Several AI APIs expose a “logit bias” parameter that lets you add or subtract from specific tokens’ scores before sampling. This is useful for keeping model outputs on-brand — for instance, forcing the model to avoid certain words or favor specific terminology — without needing to restructure your prompt. It operates at the probability engine level rather than relying on instruction-following behavior.
Probability Distribution Formation
The logit vector is passed through a softmax function, which converts the raw scores into a valid probability distribution. Every token in the vocabulary gets a probability value; all values sum to exactly 1.0.
Tokens with higher logit scores receive disproportionately higher probabilities. The softmax function exponentiates each score before normalizing, so even small differences in logit values produce meaningful differences in probability.
This is why an AI will generate a plausible-sounding response even to an impossible question. If you ask for “the biography of the first person to walk on the sun,” the model must assign probabilities to every possible next token regardless of factual coherence. It will pick the highest-probability continuation — which will be a confident, well-structured fiction — because the model has no mechanism to first evaluate whether the premise is true before generating.
Key takeaway
The model selects a continuation according to the probability distribution produced during inference.
It does not independently verify whether the underlying premise is true.
For more on why this produces inconsistent outputs, see: Why AI Tools Give Wrong Answers.
Token Selection
With probabilities computed, the system selects the next token. The two parameters that control this selection — Temperature and Top-P — are the most important levers you have for adjusting output behavior.
Temperature
Temperature scales the logit values before softmax is applied. A low temperature (e.g., 0.1–0.3) sharpens the distribution — the highest-probability tokens dominate, making outputs more deterministic. A high temperature (e.g., 1.0+) flattens the distribution — lower-probability tokens become more likely, producing more varied and sometimes creative outputs.
Top-P (Nucleus Sampling)
Top-P restricts sampling to the smallest set of tokens whose combined probability exceeds the threshold P. At Top-P = 0.9, the model considers only the tokens that account for the top 90% of the probability mass, discarding the long tail of improbable tokens. This prevents the model from occasionally selecting very unlikely tokens even when temperature is elevated.
| Use Case | Recommended Temperature | Recommended Top-P | Why |
|---|---|---|---|
| Fact-checking / Technical Documentation | 0.1–0.3 | 0.8 | Reduces randomness; outputs stay closer to high-probability continuations and improve consistency. |
| Blog Drafts / Summaries | 0.6–0.8 | 0.9 | Allows natural variation in wording while preserving coherence and structure. |
| Poetry / Creative Fiction | 1.0–1.3 | 0.95 | Encourages lower-probability token choices, producing more surprising and creative outputs. |
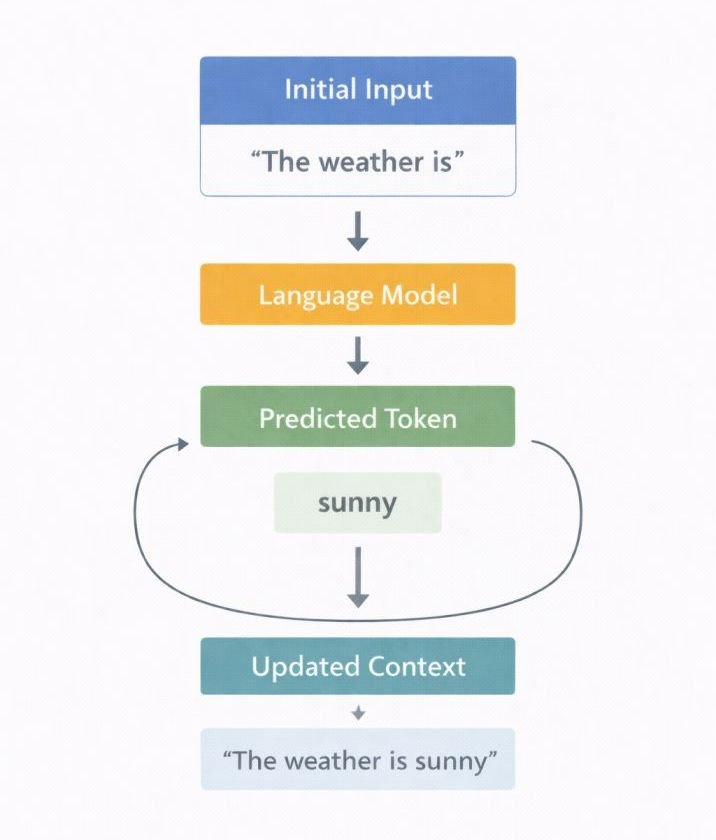
Autoregressive Loop
After a token is selected, it is appended to the sequence and the entire updated sequence is fed back into the model as the new input. The model then computes probabilities for the next token given this extended context. This loop repeats until the model generates a stop token or reaches the maximum output length.
This means that every token the model generates influences all subsequent tokens. An early poor choice can cascade through the rest of the response — which is why the first few tokens of a generation matter disproportionately.
Practical fix: Four common output problems
Vague output → Add structural constraints to your prompt (headings, numbered steps, word limits).
Hallucinated facts → Lower Temperature to 0.2 and provide the reference facts in the prompt itself.
Generic phrasing → Include concrete examples in the prompt; the model will pattern-match on them.
Missed intent → Frame the prompt as a specific task with a deliverable, not a topic (“Write a 3-paragraph explainer for a non-technical CFO” vs. “Explain AI”).
Output Assembly
Once the generation loop ends, the accumulated token IDs are decoded back into text. This involves reversing the tokenization: merging subword fragments, restoring spacing, and handling special tokens that encode punctuation or formatting.
This decoding step is largely mechanical, but it can introduce minor artifacts — occasional extra spaces, inconsistent hyphenation, or abrupt transitions — particularly in longer outputs where the model has drifted from the early context. These are cosmetic issues and do not reflect a failure in the generation pipeline; they reflect the seams where subword tokens rejoin.
The decoded text is then returned to the interface. What you see as a “response” is the end product of the full pipeline described above.
Testing Methodology
The practical observations in this guide come from exploratory prompt testing conducted across multiple AI models to identify recurring behavior patterns.
Models tested
GPT-4o, Claude 3 Opus, Gemini 1.5 Pro
Total prompt variants
52 exploratory prompt tests across four task categories designed to identify recurring behavior patterns rather than statistically representative outcomes.
Task categories
Factual recall (13 variants) · Summarization (14 variants) · Creative writing (12 variants) · Instruction following (13 variants)
Observation criteria
Output accuracy against a known ground truth; structural coherence; hallucination rate; sensitivity to temperature changes (0.1, 0.5, 0.8, 1.2 tested per variant where applicable)
Example evaluation workflow
Prompt tested:
“Summarize this article in five bullets.”
What was checked:
- Did the AI follow the instruction correctly?
- Were the facts accurate?
- Did it invent or hallucinate information?
- Was the response complete and well-structured?
Limitations
Testing was conducted by a single researcher without a control group. Results reflect observed patterns, not statistically validated findings. Model behavior varies by version and API configuration.
Common Failure Patterns Observed Across 52 Prompt Tests
This section is the most direct output of the prompt testing described in the methodology above. Every pattern below was observed repeatedly across multiple models and task categories — not inferred from documentation.
| Failure Pattern | Root Cause in Pipeline | Observed Example | Which Models | Fix That Worked |
|---|---|---|---|---|
| Vague answers despite specific question | Broad probability distribution from under-constrained prompts (Step 9) |
"Explain machine learning" → definition-level response with little depth | All three |
Add output format constraints:"Explain in 4 steps, each with one real example" |
| Lost instructions in long prompts | Context dilution across transformer layers; instruction priority weakens in long sequences (Step 6) | 500-word prompt with formatting rule at line 3 → rule ignored in output | GPT-4o, Gemini | Move critical instructions closer to the generation point rather than burying them early in the prompt |
| Confident hallucination on impossible premise | Softmax produces probabilities regardless of factual validity (Step 8) |
"Write a biography of the first human to walk on the sun" → detailed fictional narrative generated confidently | All three |
Prepend:"If the premise of this question is factually incorrect, say so before answering." |
| Character-counting errors | Tokenization splits words before character-level reasoning occurs (Step 3) |
"How many r's in Strawberry?" → answered “2” (correct: 3) | All three | Ask the model to spell the word letter-by-letter first, then count |
| Factual drift in long creative outputs | Early factual errors cascade through the autoregressive loop (Step 9) | 500-word technical summary → first section accurate, later sections introduce fabricated statistics | All three (more noticeable at Temperature 0.8+) |
Lower Temperature to 0.2–0.3 for factual tasks and split long outputs into smaller prompted sections |
Key finding from testing
Practical observations in this guide are based on exploratory prompt testing designed to identify recurring patterns rather than controlled scientific results.
Results varied by model and task type, but the pattern appeared repeatedly across multiple tests.
Test period:
April–May 2026
Environment:
Web interfaces using default model settings unless otherwise specified
What You Can Do Immediately
After understanding this process:
✓ Give AI specific instructions
✓ Break complex requests into smaller steps
✓ Add examples when you want a particular style or format
✓ Verify important information independently
✓ Treat confident wording as a signal, not proof
Key Takeaway
AI does not retrieve perfect answers from a hidden database.
It predicts likely continuations based on patterns.
Once you understand that difference, AI behavior becomes easier to explain, control, and verify.
Summary
When you click “Generate,” your text passes through a ten-stage computational pipeline in milliseconds. Understanding each stage — not just the output — changes how you interact with these tools.
The key insight to carry forward: AI generates responses through probabilistic token prediction, so important information still requires verification. Every confident-sounding statement is the output of a probability engine that selects the most likely continuation — not a truth-checked claim. This is not a flaw to work around; it is the mechanism. Understanding this helps you write better prompts, interpret outputs more carefully, and verify important information.
Understanding this helps you write better prompts, interpret outputs more carefully, and verify important information.
Pipeline Stage Reference
| Stage | Internal Operation | What Can Go Wrong |
|---|---|---|
| Input Reception | Prompt transmitted to server | Network timeout; oversized payload rejected |
| Prompt Preprocessing | Text normalized and validated | Encoding issues; silent truncation of long prompts |
| Tokenization | Text split into token IDs | Character-level tasks fail; rare words fragment unpredictably |
| Token Embedding | IDs mapped to vector representations | Out-of-vocabulary concepts produce weak representations |
| Positional Encoding | Order signals added to vectors | Very long sequences may degrade positional accuracy |
| Transformer Layers | Cross-token context computed | Early context diluted in very long generations |
| Logit Generation | Vocabulary scores assigned | Miscalibrated scores produce confident wrong answers |
| Probability Formation | Softmax normalizes scores | Model generates plausible fiction for impossible premises |
| Token Selection | Next token chosen per Temperature / Top-P | High Temperature causes factual drift; early bad tokens cascade |
| Output Assembly | Tokens decoded to text | Minor spacing/hyphenation artifacts in long outputs |
- High-stakes decisions — situations where errors have real-world consequences, such as medical, legal, or financial matters.
- Current events and live data — information that may have changed after the model’s training period or requires real-time updates.
- Specific statistics and citations — AI can generate realistic-looking numbers, references, or sources that may not actually exist.
- Future predictions — AI does not possess forecasting ability; confident predictions are generated from pattern extrapolation rather than genuine analysis.
This process is structurally related to how inference operates: Inference in AI Tools
Frequently Asked Questions
What is tokenization in AI text generation?
Tokenization converts input text into smaller units called tokens. These can be complete words, parts of words, or punctuation marks that AI models process mathematically.
How does AI generate text?
AI generates text by converting prompts into tokens, processing relationships through transformer layers, calculating probabilities, and repeatedly predicting the most likely next token.
Why does AI sometimes give different answers to the same prompt?
AI can generate different responses because token selection involves probabilities and parameters such as temperature. Small prompt changes can also influence the output.
Why can AI sound confident when it is wrong?
AI predicts likely word sequences rather than verifying truth. A response can sound fluent and confident even when the information is inaccurate.
What role do transformer layers play in AI text generation?
Transformer layers analyze relationships between tokens and build contextual understanding, allowing the model to generate relevant responses.
Does AI understand meaning like humans do?
Current AI systems do not understand meaning in the human sense. They generate outputs by recognizing statistical patterns in data and predicting likely continuations.
What does T2T mean in AI?
T2T stands for Text-to-Text. A text-to-text AI model receives text as input and produces text as output. ChatGPT, Claude, and Gemini are examples of text-to-text systems.
What is an embedding model?
An embedding model converts text into numerical vectors that represent semantic meaning. Unlike a text generation model, it does not generate sentences. It creates vector representations used for semantic search, recommendation systems, clustering, and retrieval.
References
Vaswani A. et al. (2017). Attention Is All You Need. Transformer architecture and self-attention. https://arxiv.org/abs/1706.03762
Jurafsky D., Martin J. (2023). Speech and Language Processing (3rd ed. draft). NLP concepts and language modeling. https://web.stanford.edu/~jurafsky/slp3/
Mikolov T. et al. (2013). Distributed Representations of Words and Phrases. Word embeddings and vector relationships. https://arxiv.org/abs/1310.4546
Raffel C. et al. (2019). Exploring the Limits of Transfer Learning with T5. Text-to-text framework. https://arxiv.org/abs/1910.10683
Brown T. et al. (2020). Language Models are Few-Shot Learners. GPT-3 and autoregressive generation. https://arxiv.org/abs/2005.14165
Related Reading
Continue learning how AI generates and manages responses:
- AI Memory vs. Context Window: Why Most People Confuse Them (And Why It Matters) — understand how context limits affect text generation.
- What Is Prompt Dilution? Why ChatGPT Ignores Your Instructions — learn how prompt quality influences AI before generation begins.
- Why AI Sounds Confident Even When It Is Wrong — explore why fluent responses are not always accurate.
- AI Tools vs. AI Models: Why ChatGPT, Gemini, and Claude Give Different Answers — see why different AI systems produce different outputs.
- What Are AI Tools: The System Logic Most Beginners Get Wrong — understand where text generation fits within a complete AI system.
Last Update: May 2026

Independent AI Behavior Researcher
Soumen Chakraborty is the founder of AI Tools Usage Guide and an independent AI Behavior Researcher. His research examines how AI systems behave in practical workflows, with a focus on instruction-following failures, prompt reliability, hallucination risks, context loss, and output reliability.