

Quick Answer: Prompt dilution happens when an AI prompt contains too much filler, excessive background information, or multiple competing instructions. As a result, the model may lose focus on the main task and generate broad, generic, or incomplete responses instead of prioritizing the most important instruction.
Introduction
You write a detailed, careful prompt. You explain everything. You add context, background, examples, and polite requests. Then ChatGPT spits out a response that completely ignores half of what you said.
Sound familiar?
You are not doing anything wrong — at least, not intentionally. What you are experiencing is called Prompt Dilution, and it is one of the most common (and most frustrating) reasons why ChatGPT ignores key parts of your instructions.
In this guide, you will learn exactly what prompt dilution is, why it happens, and how to reduce it significantly. If you are new to AI prompting, start with our guide on AI Tools vs. AI Models: Why ChatGPT, Gemini, and Claude Give Different Answers.
What is Prompt Dilution?
Quick Definition: Prompt dilution is an AI failure mode where core instructions get buried or ignored because a prompt is overloaded with excessive background text, conversational padding, or multiple competing tasks. This dilutes the AI’s attention mechanism, leading to generic or incomplete responses.
In simple terms, prompt dilution happens when a prompt contains excessive background information, competing ideas, or unnecessary filler that reduces the importance of the core instruction.
Think of it this way: imagine giving someone a 10-step task verbally, but you bury the most important step inside a five-minute story. By the time you finish talking, they have forgotten Step 4 entirely.
That is essentially what happens inside an AI language model’s context window. When a prompt is crowded with competing information, the model may treat multiple instructions as equally important to multiple competing instructions — and your actual command stops standing out.
Why ChatGPT Ignores Instructions
Prompt dilution is one of the most common reasons ChatGPT appears to ignore instructions.
When a prompt contains excessive background information, multiple objectives, or competing requirements, the model may distribute attention across several signals instead of prioritizing the main task.
As a result, users often experience:
- Missing requirements
- Generic responses
- Incomplete outputs
- Ignored formatting instructions
- Partial task completion
This does not necessarily mean the model failed. In many cases, the prompt failed to establish a clear instruction hierarchy.
The Technical Mechanism Behind the Failure
What Research and AI Documentation Suggest
Modern AI systems based on transformer architectures process information using attention mechanisms that determine which parts of an input receive greater weighting during response generation. Research on large language models suggests that when prompts contain competing instructions, excessive background information, or unclear priorities, important signals can become less prominent relative to surrounding content.
Practical guidance from major AI providers also consistently recommends structured instructions, explicit task boundaries, and clear formatting requirements because these help reduce ambiguity and improve instruction-following behavior.
This does not mean a model literally “forgets” earlier instructions. Instead, certain instructions may receive less emphasis relative to other competing information inside the prompt.

There are three main technical reasons behind this behavior:
1. Context Window Overload
Every AI model has a context window — a limit on how much text it can actively process at once. When your prompt fills that space with padding, backstory, and repetition, earlier or less prominent instructions may receive less emphasis relative to newer or competing information.
Related: Understanding AI context windows and token limits
2. Attention Dilution
When prompts contain many competing ideas, instructions, or objectives, the model may assign similar weighting across multiple signals instead of strongly prioritizing one. As a result, the main task can become less prominent within the overall prompt.
Related: Instruction Conflict in AI Workflows: Operational Prompt Testing
3. Instruction Burial
If your actual instruction is sandwiched between long paragraphs of context, the model may treat the surrounding text as more significant simply because there is more of it. The instruction can become less prominent relative to surrounding context and may receive less emphasis in the response.
Where This Causes the Most Damage: Practical Examples
The clearest way to see prompt dilution in action is to compare the same request written two different ways — once with clutter, once without.
Example 1: The Bloated Code Review Prompt
I have been working at a fintech startup for about three years now and we recently
migrated our backend from Django 2.x to Django 4.2. During the migration we ran into
some issues with our authentication layer. My team lead asked me to do a security audit
of some of our older utility functions before we push to production next Friday. I know
you are really good at this kind of thing and I have used you before for code reviews.
Anyway, here is the function. I want to know if it is safe. Also if you have any
suggestions for improving the readability that would be great too. And maybe if there
are performance issues? Here is the code:
def get_user_token(user_id, db_conn):
query = f"SELECT token FROM users WHERE id = {user_id}"
result = db_conn.execute(query)
return result.fetchone()[0]What tends to happen: The prompt asks for security, readability, and performance — and the model tries to give you all three. In practice, this means you often get lengthy style suggestions and performance commentary while the critical issue (a SQL injection vulnerability on Line 2) gets buried or skipped entirely. The model followed your instructions — just not the most important one.
CONTEXT: Security audit only. Exclusionary rule: Do not analyze style, readability, or performance.
TASK: Identify all critical application vulnerabilities within the provided Python function.
FUNCTION:
def get_user_token(user_id, db_conn):
query = f"SELECT token FROM users WHERE id = {user_id}"
result = db_conn.execute(query)
return result.fetchone()[0]
OUTPUT FORMAT: List findings using: [Severity] / [Type] / [Line] / [Fix]What tends to happen now: With competing instructions removed, the model typically leads with the SQL injection vulnerability, flags it as critical, and delivers a parameterized query fix — without detours into formatting advice.
Why the structured prompt performs better:
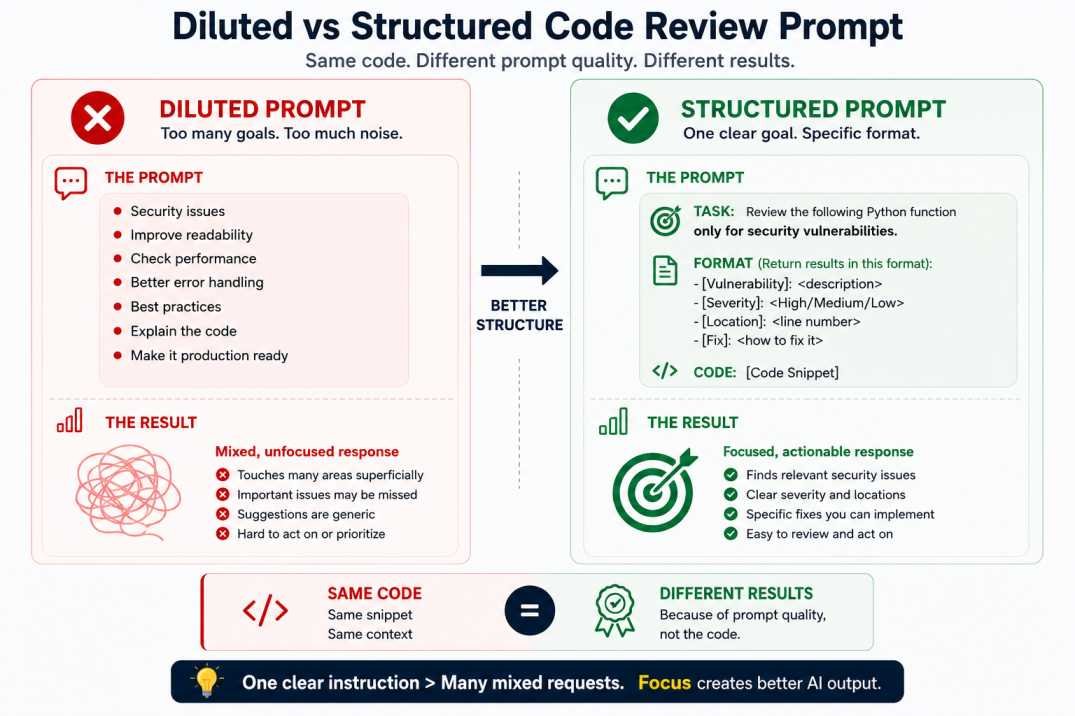
- Removes competing goals — security, readability, and performance are no longer fighting for the same response
- Sets an exclusionary boundary — telling the model what not to do is often as important as telling it what to do
- Specifies output format —
[Severity] / [Type] / [Line] / [Fix]leaves no room for essay-style responses - Reduces ambiguity — the model has one job, clearly defined
Example 2: The Unfocused Data Analysis Request
Hi! So I have this CSV file with customer data from our SaaS platform. We have been
having some issues with churn lately and my manager wants a report by end of week.
The dataset has columns like user_id, signup_date, last_login, subscription_tier,
support_tickets_count, monthly_spend, churned (boolean).
Here is a sample of the data: [data paste]What tends to happen: The open-ended phrase “understand our customers better” pulls the model toward generic exploratory analysis — mean averages, basic bar charts, summary statistics. The specific behavioral signals that actually predict churn (like a sudden drop in login recency combined with a spike in support tickets) often go unexamined because no one told the model to look for them specifically.
CONTEXT: SaaS customer dataset. Operational boundary: Churn prediction analysis only.
Skip general exploratory statistics.
TASK: Identify the top 3 specific behavioral signals that correlate most strongly with
churned = True. Evaluate: last_login recency, support_tickets_count, monthly_spend
trend, and subscription_tier.
OUTPUT FORMAT:
1. Correlation direction and relative strength in plain English.
2. Interaction patterns (e.g., compounding risk scenarios).What tends to happen now: By excluding exploratory statistics, the model focuses on directional risk. A common result is that outputs home in on login recency as a primary signal and surface the compound pattern of high ticket volume combined with declining spend — which is the actionable insight the analyst actually needed.
Why the clean version works:
- Names the specific columns to evaluate — removes guesswork about what matters
- Excludes generic EDA — prevents the model from defaulting to the easier, more familiar task
- Asks for interaction patterns explicitly — compounding risk signals are often the most valuable finding, but the model won’t surface them unless asked
- Keeps the scope narrow — one analytical objective, not three
Example 3: The Over-Contextualized API Debug Request
We are integrating with the Stripe API for our payments flow. Recently we pushed a new feature
that lets users update their subscription tier from within the app. Since that release
we have been getting intermittent 429 errors. I read the Stripe docs and I know 429
means rate limiting but I am not sure why it is suddenly happening now. We are using
the Python stripe library version 5.x. I want to understand why this is happening,
how to fix it, and maybe some general best practices for API rate limit handling.
Here is our code: [code paste]What tends to happen: The phrase “general best practices for API rate limit handling” is an open invitation for a textbook response. The model often spends most of its output explaining what exponential backoff is and how HTTP 429 works in theory. The actual architectural flaw — unbatched, synchronous API calls inside a loop triggered by the new tier-change feature — tends to appear at the bottom of the response, if at all.
CONTEXT: Stripe API integration error tracking (Python stripe v5.x). Production event:
Intermittent HTTP 429 rate-limiting errors started immediately after deploying the
tier-change function.
TASK: Analyze the provided code block exclusively for architecture flaws that trigger
rate limits. Inspect for synchronous loops, missing idempotency keys, or unbatched
endpoint hits.
OUTPUT FORMAT: Root Cause Analysis followed immediately by Implementation Fix. Skip
all rate-limiting definitions or status code theory.What tends to happen now: The constraint against definitions appears to push the model past broad theoretical explanations. A more targeted prompt is more likely to surface architectural issues such as repeated endpoint calls, synchronous loops, missing idempotency controls, or request patterns that could trigger rate limits. Instead of spending most of the response explaining HTTP 429 theory, the output stays focused on diagnosis and implementation-level fixes.
Why the clean version works:
- Anchors the timeframe — “errors started immediately after deploying the tier-change function” tells the model exactly where to look
- Names the failure modes to inspect — synchronous loops, missing idempotency keys, unbatched endpoint hits
- Explicitly bans definitions — models default to explaining concepts when they detect an unfamiliar error; this overrides that default
- Demands root cause first — output format forces diagnosis before prescription
What These Examples Have in Common

Across all three examples, the same underlying pattern appears:
Diluted prompts fail because narrative background competes with the instruction for the model’s attention. When everything feels equally important, nothing is treated as a priority. Prompts that separate Context, Task, and Output Format create a clearer instruction hierarchy and generally produce more targeted outputs.
| Prompt Type | Characteristics | Typical Response |
|---|---|---|
| Diluted Prompt | Long backstory, filler, bundled tasks, vague requests | Responses become broad, unfocused, or miss important instructions |
| Structured Prompt | Clear task boundaries, minimal filler, single objective | Responses stay focused, precise, and aligned with the requested task |
What Repeated Prompt Testing Revealed
Across repeated prompt testing, two patterns appeared consistently:
1. Multiple objectives reduced output precision
When a prompt simultaneously requested several outcomes — such as security analysis, readability feedback, visualizations, and recommendations — responses often became broader but less focused. The model attempted to satisfy every instruction instead of prioritizing the most critical objective.
2. Permission-style phrases often increased filler
Phrases such as:
- “if possible”
- “maybe also”
- “it would be nice if”
frequently produced longer responses with additional explanation sections that were not central to the task.
The strongest improvement came from replacing open-ended permission language with explicit boundaries and exclusions. Clear instructions about what not to do often improved output quality as much as instructions about what to do.
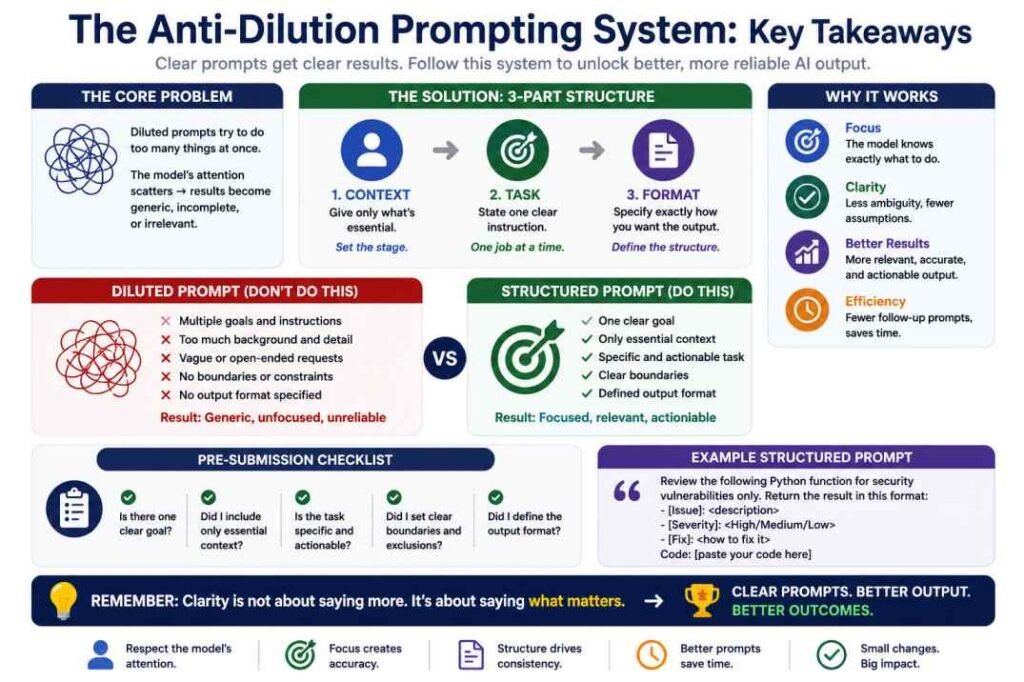
The CTF Framework: A Simple Way to Prevent Prompt Dilution
Across repeated testing, most prompt dilution problems can be reduced using a simple structure:
C = Context
T = Task
F = Format
Context:
Provide only the background information required to understand the task.
Task:
State one primary objective.
Format:
Specify exactly how the response should be structured.
Example:
CONTEXT:
Customer support email.
TASK:
Identify the main complaint.
FORMAT:
Return:
- Complaint summary
- Severity level
- Recommended action
This structure creates a clear instruction hierarchy and reduces attention competition.
The Fix: Three Rules That Eliminate the Problem
The fix is simpler than you think. Follow these three rules:
Rule 1: Put Your Core Instruction First
Do not warm up. Do not introduce yourself. Lead with the command.
❌ Diluted: “Hi! I hope you are doing well. I have been using AI for a while now and I find it really useful. Could you write me a product description for my new coffee mug?”
✅ Clean: “Write a 100-word product description for a ceramic coffee mug. Target audience: home baristas. Tone: warm and conversational.”
Rule 2: Use Structured, Minimal Language
Strip your prompt to its skeleton. Every sentence should earn its place.
Ask yourself: If I deleted this sentence, would the output change? If the answer is no, delete it.
Rule 3: Separate Context from Command
If you genuinely need to provide background, separate it clearly:
CONTEXT: [one to two sentences of essential background]
TASK: [your actual instruction]
FORMAT: [how you want the output structured]
This gives the model a clear hierarchy. It knows what to do and what is just reference material.
💡 Master the Next Step: Eliminating prompt dilution gives you a highly focused AI draft. However, turning that raw output into a polished, high-converting piece of writing still requires a human-grade editing system. To master this process, we highly recommend New York Times bestselling author Joshua Lisec’s masterclass: The Best Way to Edit AI & Re-Human Your Writing. It delivers a step-by-step, 90-minute framework to remove robotic footprints and protect your authentic voice.
Pre-Submission Checklist

Before you submit any prompt, run through this:
- [ ] Is my core instruction in the first or second sentence?
- [ ] Have I removed all unnecessary background and pleasantries?
- [ ] Am I asking for only one primary output (not three tasks bundled together)?
- [ ] Are my requirements specific, not vague?
- [ ] Is my prompt under 200 words unless complexity genuinely demands more?
If you can check all five boxes, your prompt is clean.
How Prompt Dilution Differs From Other Prompt Failures
Prompt dilution is different from instruction conflict and prompt ambiguity.
Instruction conflict happens when prompts contain competing instructions that directly contradict each other.
Prompt ambiguity happens when instructions are too vague or undefined.
Prompt dilution happens when excessive context, filler, or multiple competing goals reduce the prominence of the main instruction.
Understanding the difference matters because each problem requires a different fix.
What This Is NOT About
It is worth clarifying: prompt dilution is not the same as writing a long prompt. Length alone is not the problem.
A 500-word prompt with dense, structured, relevant information will outperform a 50-word vague prompt every time. The issue is irrelevant length — padding that competes with your real instruction for the model’s attention.
Prompt Dilution vs Prompt Ambiguity
These two problems are often confused, but they are different failure modes.
| Factor | Prompt Dilution | Prompt Ambiguity |
|---|---|---|
| Main Problem | Too much competing information or unnecessary context | Instructions are unclear or open to multiple interpretations |
| Typical Cause | Backstories, filler text, bundled tasks | Vague wording, missing constraints, undefined goals |
| Common AI Behavior | Responses become broad, generic, or miss priorities | Responses vary because the model interprets intent differently |
| Example | “Review security, readability, performance, and suggest improvements.” | “Make this better.” |
| Fix | Reduce clutter and isolate one primary objective | Add specificity and measurable instructions |
Prompt dilution creates too many signals competing for attention. Prompt ambiguity creates signals that are not defined clearly enough. The fixes are different, which is why identifying the correct problem matters.
Important Limitation
Even well-structured prompts do not guarantee correct answers. AI models can still generate inaccurate information, miss important context, or confidently present wrong conclusions. Prompt structure improves reliability, but it does not replace verification. For a deeper explanation of misleading but confident outputs, read Hallucination of Authority: When AI Sounds Right but Is Wrong (Case Study + Prevention Guide).
How to Diagnose Prompt Dilution in 30 Seconds
Ask yourself:
□ Am I asking for more than one primary task?
□ Did I include a long backstory?
□ Does the prompt contain phrases like:
“if possible”
“maybe also”
“it would be nice if”
□ Is the actual instruction buried in the middle?
□ Did I specify an output format?
If you answered yes to two or more questions, prompt dilution is likely affecting your results.
Prompt Dilution vs Other Prompt Failures
| Failure Mode | Main Cause | Typical Symptom |
|---|---|---|
| Prompt Dilution | Too much competing information | Instructions ignored |
| Prompt Ambiguity | Unclear request | Unpredictable answers |
| Instruction Conflict | Contradictory instructions | Mixed outputs |
| Context Loss | Long conversation history | Earlier details forgotten |
Frequently Asked Questions (FAQ)
What is the main cause of prompt dilution?
The main cause is including excessive conversational filler, irrelevant background stories, or multiple competing instructions in a single prompt. This overloads the AI’s context window and splits its attention mechanism, causing it to ignore your core command.
How long should a clean prompt be to avoid dilution?
Length alone is not the problem. A clean prompt can be long if it contains highly structured, relevant information. However, for standard tasks, keeping your prompt under 200 words and removing all unnecessary pleasantries is highly recommended.
Does structured prompt layout guarantee 100% accurate AI responses?
No, structure improves instruction reliability but does not eliminate hallucinations. AI models can still generate inaccurate information or miss context, so manual verification of the output is always required.
What is the best way to separate context from commands in a prompt?
The best way is to use clear markdown headers or uppercase labels like CONTEXT:, TASK:, and OUTPUT FORMAT:. This creates a clear visual and logical hierarchy that the AI model can easily prioritize.
Related Reading
Prompt dilution rarely occurs in isolation.
Many users confuse it with instruction conflict, context loss, or prompt ambiguity.
To understand the differences, continue with:
- Best ChatGPT Prompts for Beginners: 10 Frameworks That Fix Generic AI Output
- Why Beginners Fail at ChatGPT: An Observational Analysis
- What Is an AI Workflow? (Simple Explanation + Real Example)
- Why AI Tools Fail (Hidden Errors Most Users Miss)
Final Thoughts
Prompt dilution is invisible until you know it exists. Once you see it, you cannot unsee it — and your AI outputs will improve dramatically.
The core principle is simple: respect the model’s attention. Give it clarity, not volume. Give it structure, not stories. Give it one clear job at a time.
Prompt dilution becomes easier to spot once you understand how AI systems prioritize instructions internally. The goal is not to write shorter prompts — it is to write clearer ones. When prompts separate context, tasks, and output requirements cleanly, AI responses become more focused, reliable, and easier to verify.

Independent AI Behavior Researcher
Soumen Chakraborty is the founder of AI Tools Usage Guide and an independent AI Behavior Researcher. His research examines how AI systems behave in practical workflows, with a focus on instruction-following failures, prompt reliability, hallucination risks, context loss, and output reliability.