
Quick Answer: AI Prompt Engineering for Teams is the process of creating structured prompting systems that help multiple employees generate consistent, reliable, and scalable AI outputs.
Instead of relying on personal prompting habits, teams use standardized templates, workflow rules, and review systems to improve output quality and reduce structured inconsistency.
Introduction
As AI adoption expands across departments, many organizations are discovering that the real challenge is not gaining access to AI models, but maintaining consistent scalable behavior across teams. Most enterprise AI initiatives do not fail because the model is “bad.” They fail because every employee interacts with the system differently.
When one employee generates a strong strategic response while another receives vague or unreliable output for the exact same task, the problem is no longer technical—it is team-based. At that point, the organization does not have a dependable prompting standard capable of supporting repeatable workflows.
This is why AI Prompt Engineering for Teams is becoming an important scalable discipline. Without shared structures, review standards, and governance rules, AI-generated work quickly turns into repeated editing cycles, fragmented communication styles, and growing distrust in output quality.
Related Research
- Prompt Design Patterns: 10 Frameworks for More Consistent AI Outputs
- Why AI Gives Wrong Answers
- What Is an AI Workflow?
Table of Contents
Why Individual Prompting Fails Inside Teams
Most users interact with AI reactively, entering a prompt and expecting a reliable result without a defined workflow structure.
- Personal Use: You know your internal context. Even a fragmented prompt works because you can fill in the gaps mentally.
- Team Operations: Every team member has a different skill level. Without a structured framework, AI outputs become fragmented and inconsistent.
Illustrative workflow example: Three employees were asked to complete the same AI-assisted task using their own prompting approaches. Despite working toward the same objective, the outputs differed significantly in tone, formatting, and factual depth. The variation was caused by inconsistent prompting rather than differences in the AI model.
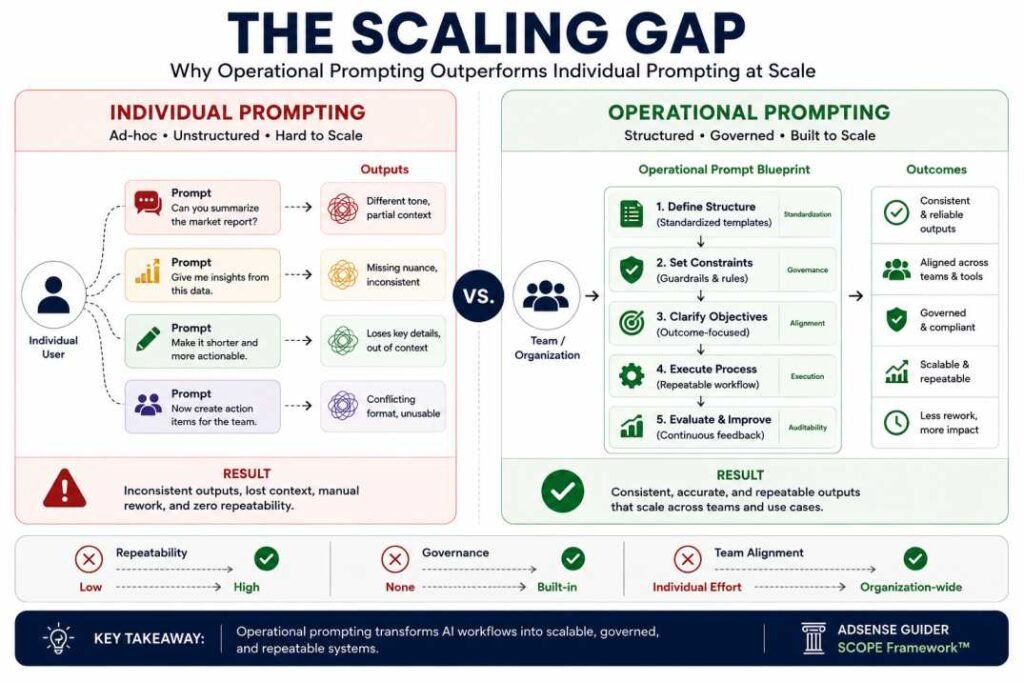
Comparison: The Scaling Gap
| Individual Prompting | Operational Prompting |
|---|---|
| Different prompt styles per employee | Shared prompt templates |
| Inconsistent outputs | Standardized outputs |
| High revision workload | Reduced editing overhead |
| Difficult to monitor | Easier governance and auditing |
| Dependent on individual skill | Scalable across teams |
The Decision Rule: If AI outputs consistently require repeated human revisions, the prompting system is probably operating at an individual level rather than an operational standard.
Well-designed prompts reduce ambiguity before work enters a team workflow. Instead of examining workflow execution, this guide focuses on how standardized prompt structures improve consistency, governance, and repeatable AI outputs across multiple users.
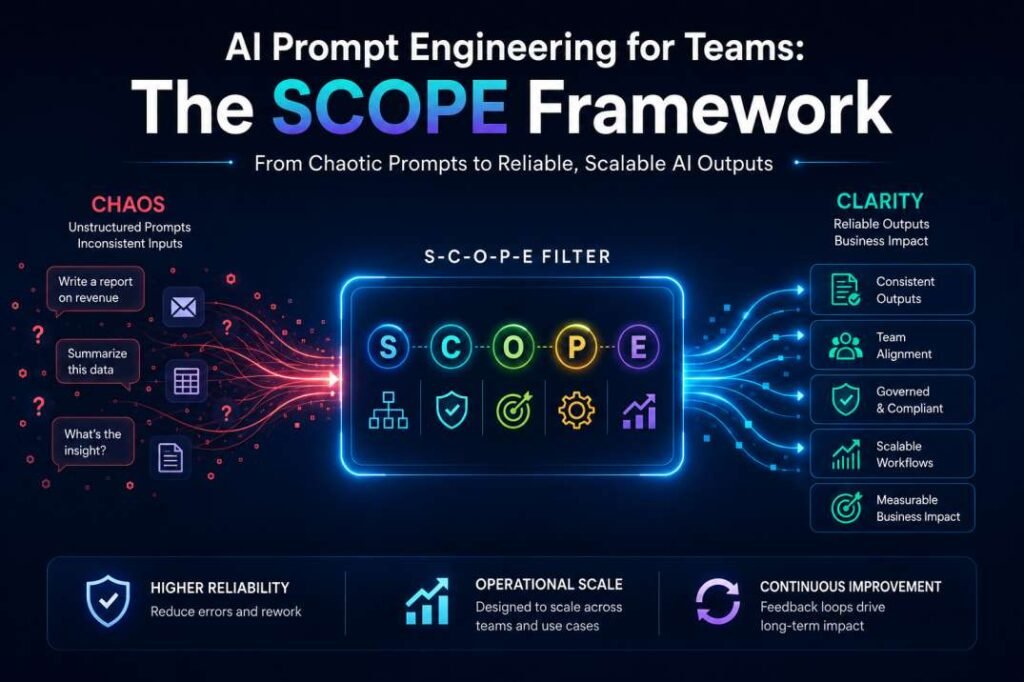
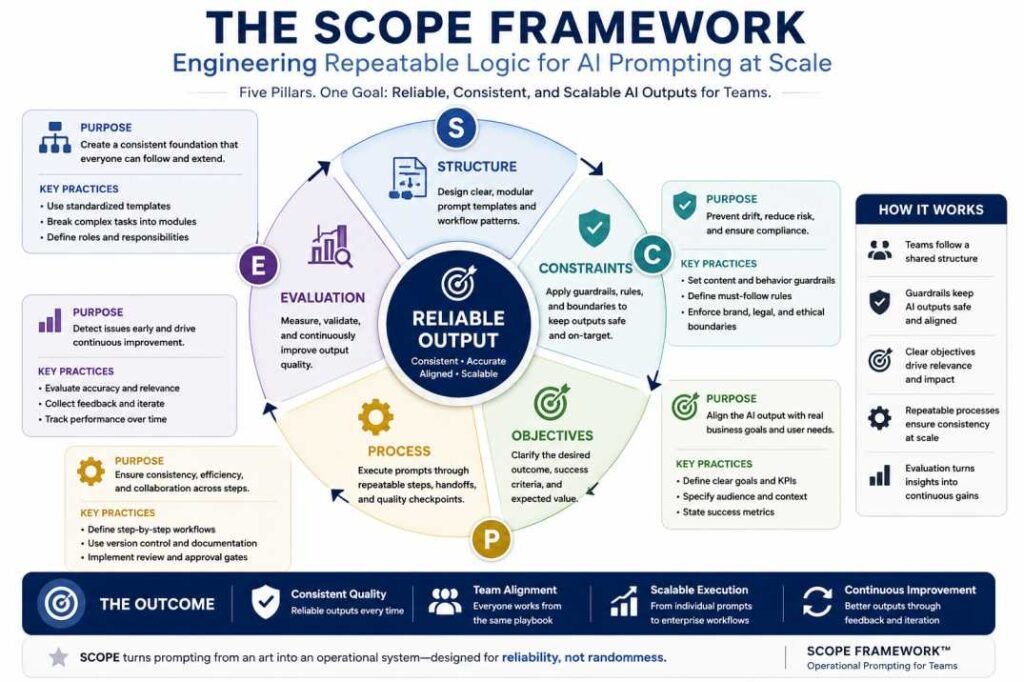
The SCOPE Framework: Engineering Repeatable Logic
To achieve consistent AI outputs across multiple employees, organizations need more than well-written prompts—they need a repeatable prompting structure. The SCOPE Framework provides a standardized template that reduces unnecessary variation while improving consistency, governance, and operational reliability.
Starter Operational Template
Role: [Department Role]
Goal: [Business Objective]
Constraints: [Word limits, compliance rules, style requirements]
Process: [Step-by-step workflow]
Output Format: [Markdown, table, JSON, report]
Evaluation: [Accuracy, completeness, policy compliance]
Weak Prompt
“Write a report about customer complaints.”
Operational Prompt
“You are a Senior Customer Operations Analyst. Review the complaint summaries, identify the three most common operational failures, and present the findings in bullet points for executive review. Keep the response under 250 words.”
S — System Role
Define the AI’s operational role before assigning the task. A clear role establishes a shared perspective, helping different team members produce more consistent outputs.
Example
“You are a Senior Customer Operations Analyst responsible for summarizing customer complaints for executive review.”
C — Constraints
Specify mandatory boundaries before generation, including word limits, compliance requirements, prohibited content, or style rules. Shared constraints reduce variation between employees.
Example
Do not include unsupported claims
- No technical jargon
- Maintain a neutral tone
- Maximum 300 words
O — Output Format
Define the required structure before generation, such as Markdown, tables, JSON, or executive summaries. Consistent formatting allows outputs to move directly into business workflows with minimal editing.
P — Process Logic
Break complex work into sequential steps rather than asking the model to complete everything at once.
Example
- Analyze the source information.
- Identify the key findings.
- Draft the summary.
- Review for completeness before finalizing.
E — Evaluation
Before accepting the output, verify that it follows the required instructions, formatting, and constraints. A simple review step helps maintain consistency across shared prompting systems.
Continue Reading
The Path to Standardization: Building a Prompt Library
A standardized prompt library helps teams move from individual prompting habits to repeatable organizational practices. Instead of creating prompts from scratch, employees start from approved templates that reflect the organization’s communication standards and operational requirements.
Prompt libraries improve consistency by separating stable instructions from task-specific information. Teams maintain one approved template while updating only the variables needed for each task.
Step 1: Centralize Approved Prompts
Store validated prompts in a shared location such as Notion, SharePoint, GitHub, or a prompt management platform. A single source of truth reduces duplicate work and makes updates easier to manage.
Step 2: Use Variables Instead of Rewriting
Convert static prompts into reusable templates.
Instead of
Write an email to John about a delivery delay.
Use
Draft an email for [Client Name] regarding [Issue Type] using [Policy Level] and include [Resolution Link].
Draft an email for ABC Manufacturing regarding a delayed shipment. Follow the Standard Customer Support Policy, explain the expected delivery timeline, and include the order tracking link.
Step 3: Maintain Version Control
Treat prompt templates as operational documents rather than personal notes. When business policies, brand guidelines, or AI models change, review and update the shared template so every team member works from the same version.
Related Reading
After prompt standards are established, the next step is implementing structured execution workflows.
→ AI Workflows for Teams: Why One-Off Prompts Fail
Human-in-the-Loop (HITL): Governance Before Approval
Even well-designed prompts cannot eliminate every error. Human review remains an essential governance layer for business-critical AI outputs, especially when responses influence customers, legal documents, financial decisions, or public communication.
The purpose of HITL is not to rewrite every response. Instead, reviewers verify that the output follows organizational standards before it is approved for use.
A practical review checklist includes:
- Required instructions were followed.
- Facts are supported where necessary.
- Sensitive or confidential information is handled correctly.
- Tone and formatting match organizational standards.
- The response is ready for its intended audience.
Organizations can apply different review levels depending on the risk of the task. Low-risk internal drafts may require only a quick review, while customer-facing or regulated content should receive a more detailed verification before publication.
Related Research
For a complete execution and validation process after prompt design, see:
AI Workflows for Teams: Why One-Off Prompts Fail

Operational Example: Standardizing Team Prompts
A marketing team producing weekly AI-assisted newsletters noticed that output quality varied significantly between employees. Although everyone worked toward the same objective, differences in prompting style resulted in inconsistent tone, formatting, and brand messaging.
To improve consistency, the team introduced three simple standards:
- A shared prompt template containing the organization’s brand guidance.
- A predefined output structure for every newsletter.
- Editable variables limited to campaign-specific information, while the core prompt remained unchanged.
After standardizing the prompting process, editors reported fewer formatting inconsistencies and a more consistent writing style across team members. The largest improvement came from reducing unnecessary prompt variation rather than changing the AI model itself.
This example illustrates an important principle: teams scale more effectively when prompting becomes a shared operational standard instead of an individual habit.
Strategic Implementation: Getting Started
Organizations do not need to redesign every AI task at once. A practical approach is to standardize one high-impact workflow before expanding to additional use cases.
A simple rollout plan is:
Phase 1 — Identify Repetitive Tasks
Choose one task that multiple employees perform regularly, such as email drafting, customer support, or content creation.
Phase 2 — Build a Shared Prompt Standard
Create one approved prompt template using the SCOPE Framework. Define the role, constraints, output format, and evaluation criteria so every team member begins with the same instructions.
Phase 3 — Review and Improve
Collect feedback from users, identify recurring issues, and update the shared template when necessary. Treat prompts as living operational documents rather than one-time instructions.
Small improvements made consistently across shared prompts usually produce greater long-term reliability than continually changing AI models.
Final Thoughts: Prompt Engineering Is an Operational Standard
As organizations adopt AI across multiple departments, the challenge shifts from generating individual responses to maintaining consistent performance across teams.
Prompt engineering should therefore be treated as an operational standard rather than a personal skill. Shared templates, defined constraints, and regular review processes reduce unnecessary variation and make AI outputs easier to manage at scale.
Prompt engineering does not guarantee accuracy, but standardized instructions create a repeatable foundation for more reliable AI workflows without relying on longer or more complex prompts.
The objective is not to write longer prompts. The objective is to create standardized instructions that produce predictable results regardless of who uses them.
If you want to learn how these standardized prompts become complete multi-step execution systems, continue with AI Workflows for Teams: Why One-Off Prompts Fail.
Frequently Asked Questions (FAQ)
Q1. Why do teams get inconsistent AI results?
Teams usually receive inconsistent AI outputs because employees use different prompting approaches, formatting preferences, and instruction styles. Standardized prompt templates reduce this variation by giving everyone the same operational starting point.
Q2. How can businesses standardize AI prompts?
Organizations typically standardize prompting by creating approved templates, defining review rules, and maintaining a shared prompt library that employees can reuse across recurring tasks.
Q3. Can prompt engineering guarantee accurate AI outputs?
No. Structured prompting improves consistency and reduces ambiguity, but it cannot guarantee factual accuracy. Human review and source verification remain necessary for high-risk or business-critical work.
Q4. How is team prompt engineering different from personal prompting?
Personal prompting depends on individual habits and experience. Team prompt engineering relies on shared templates, standardized instructions, and governance practices so multiple employees can produce consistent outputs.
Q5. Is prompt engineering the same as an AI workflow?
No. Prompt engineering focuses on designing clear, standardized instructions for AI systems. AI workflows define how those prompts are used within a broader process that may include research, drafting, validation, and human review.
For implementation guidance, see AI Workflows for Teams: Why One-Off Prompts Fail.
Resources & Further Reading
- OpenAI Prompt Engineering Best Practices: A comprehensive guide on strategies to get better results from large language models.
- Anthropic Prompt Engineering Documentation: Detailed insights into building reliable workflows specifically with Claude and other advanced models.
- NIST AI Risk Management Framework: The widely used framework for managing risks and ensuring the reliability of artificial intelligence systems in enterprise environments.
- Microsoft Prompt Engineering Guidance: Technical documentation on maximizing the performance and safety of AI deployments at scale.

Independent AI Behavior Researcher
Soumen Chakraborty is the founder of AI Tools Usage Guide and an independent AI Behavior Researcher. His research examines how AI systems behave in practical workflows, with a focus on instruction-following failures, prompt reliability, hallucination risks, context loss, and output reliability.