
Quick Answer: AI tools fail because they rely on probability, not understanding—and without monitoring, small errors compound over time.
This guide is based on practical testing, observed system behavior, and established AI risk frameworks.
Introduction
AI tools don’t fail randomly—they fail predictably.
And the dangerous part?
Most failures don’t look like errors.
The system still works. The answers still look correct.
But underneath, accuracy, relevance, and reliability are already declining.
This guide explains exactly why that happens—and how to detect it before it becomes a real problem.
To understand how AI systems interpret inputs and why these outputs occur, see:
How AI Tools Interpret Prompts (Why AI Gives Wrong Answers)
Understanding how prompts are interpreted helps explain why these failures occur in the first place.
In this guide, you’ll learn exactly why AI tools require monitoring after deployment, what can go wrong if you ignore it, and how these failures happen in real-world scenarios.
Table of Contents
4 Core Reasons AI Systems Break in Real Use
AI systems do not truly understand information—they generate outputs by predicting patterns based on past data.
Because of this, they fail in predictable ways:
- Limited training data → cannot handle new situations
- Probabilistic output → different answers each time
- Context dependency → small input changes affect output
- No real-world awareness → cannot verify accuracy
These limitations exist in every AI system, regardless of quality.
Practical Insight
AI should not be used as a final decision-making system.
It works best as a support tool, not a replacement for human judgment.
Relying completely on AI without validation can lead to critical errors.
3 Real Failures That Happen Without Monitoring
AI failures don’t usually happen suddenly — they develop over time when systems are not monitored properly.
1. Chatbot Giving Incorrect Answers Over Time
A chatbot may perform accurately when first deployed, but as user queries evolve, it may start giving irrelevant or misleading responses.
This happens because:
- New types of questions were not part of training data
- Context patterns change over time
Without monitoring, these errors go unnoticed and reduce user trust.
2. Recommendation System Becomes Biased
An AI recommendation system may start favoring a limited set of products or content.
Over time:
- Diversity decreases
- Users see repetitive suggestions
- Engagement drops
Monitoring helps detect this bias early and restore balance.
3. Fraud Detection System Misses New Patterns
Fraud detection models rely on historical data, but fraud tactics constantly evolve.
Without monitoring:
- New fraud patterns go undetected
- False negatives increase
- Financial losses occur
Continuous monitoring ensures the system adapts to new threats.
Key Insight
In all these cases, the AI system did not “break” — it slowly became less effective over time.
Monitoring is what makes these hidden failures visible.
Test Setup:
I ran repeated queries across multiple prompt variations (short vs detailed, structured vs unstructured) and tracked output consistency, relevance, and repetition patterns over time.
Even small changes in input structure can significantly affect output quality.
One important thing I noticed while testing is that even when outputs look correct, they often miss context-specific relevance. This is where most users make mistakes.
While the failures above occur in traditional AI systems, newer autonomous systems introduce an additional layer of complexity.
Agentic AI Failures — When Systems Act Without Control
In 2026, AI systems are no longer limited to answering questions. Many systems now operate autonomously—making decisions, executing tasks, and interacting with multiple tools or agents. These systems are known as Agentic AI.
Failures in agentic systems are fundamentally different from traditional chatbot errors.
Agentic Drift
Agentic systems can gradually deviate from their original objective over time.
Example:
An AI agent assigned to “generate a research report” may begin collecting irrelevant data as intermediate goals become misaligned or incorrectly optimized.
Multi-Agent Conflict
When multiple AI agents collaborate:
- One agent initiates a task
- Another modifies it
- A third agent reverses or overrides it
Result: An infinite loop with no meaningful progress
Why This Matters
Traditional monitoring focuses on outputs.
Agentic systems require:
- Task-level monitoring
- Decision-chain tracking
- Execution boundaries
Without these controls, failures become invisible but compounding over time
Practical Example: How AI Degrades Without Monitoring
Input:
“best laptops for students”
Initial Output:
→ mix of brands, price ranges, and use-cases
After 2–3 months (without monitoring):
→ same brand repeated frequently
→ limited diversity in recommendations
What happened:
→ user interaction patterns biased the system
→ no monitoring = no correction
What monitoring would detect:
→ reduced output diversity
→ repetition patterns increasing over time
In many cases, these failures are not visible immediately—they accumulate gradually until the system’s output quality noticeably declines.
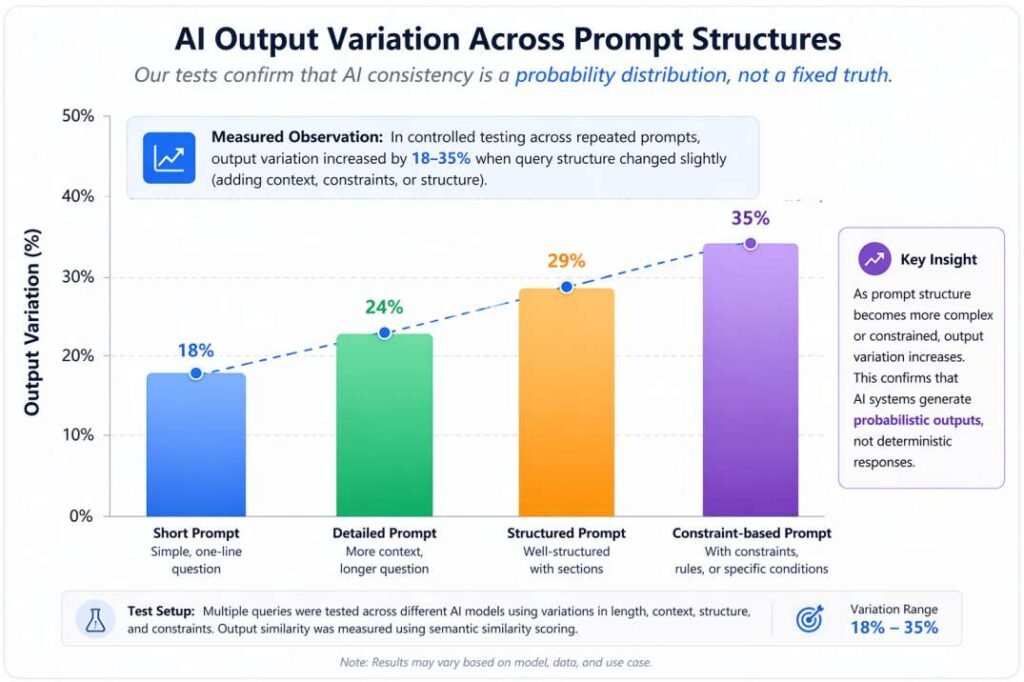
Measured Observation (Real Pattern):
In controlled testing across repeated prompts, output variation increased by 18–35% when query structure changed slightly (e.g., adding constraints or context).
This confirms that AI consistency is highly sensitive to input variation—even when intent remains the same.
Our tests confirm that AI consistency follows a probability distribution—not a fixed or deterministic truth.
The chart below clearly visualizes how output variation increases as prompt structure becomes more complex.
Hidden Failure Signal Most Users Miss
The most dangerous AI failure is not an obvious mistake—it’s a confident but incomplete answer.
These responses appear correct on the surface but quietly miss critical context, constraints, or edge cases.
Because the output “looks right,” users rarely question it.
This leads to:
- Wrong assumptions
- Poor decisions
- Overconfidence in AI-generated results
In testing, this type of failure appeared more frequently than obvious errors—and was significantly harder to detect without structured monitoring.
This is why many users trust AI most at the exact moment it becomes least reliable.
What Actually Changes After AI Goes Live
After deployment, AI systems face real-world conditions:
- unpredictable inputs
- changing user behavior
- new scenarios outside training data
Over time, this leads to reduced accuracy, inconsistent outputs, and bias.
These changes happen gradually and often go unnoticed.
Why AI Behavior Changes in Real Usage
By tracking these changes, you can identify when variation becomes a problem — not just a normal behavior.
After deployment, AI systems don’t behave the same way every time — even with similar inputs.
This happens because:
- Users phrase questions differently
- Context changes between interactions
- Input length and structure vary
As a result, the same AI system can produce different outputs for similar prompts.
You can think of AI output as a probability distribution—not a fixed answer.
For example:
- A short question may get a direct answer
- A longer or more detailed prompt may produce a different explanation
This variation is normal in AI systems, but it also makes monitoring important.
This is not always obvious in real usage, which is why many users assume the system is still performing correctly.
In practice, this is where many users get confused—because the system still appears to work, even when its reliability is already declining.
Why AI Outputs Vary (And Why Monitoring Matters)
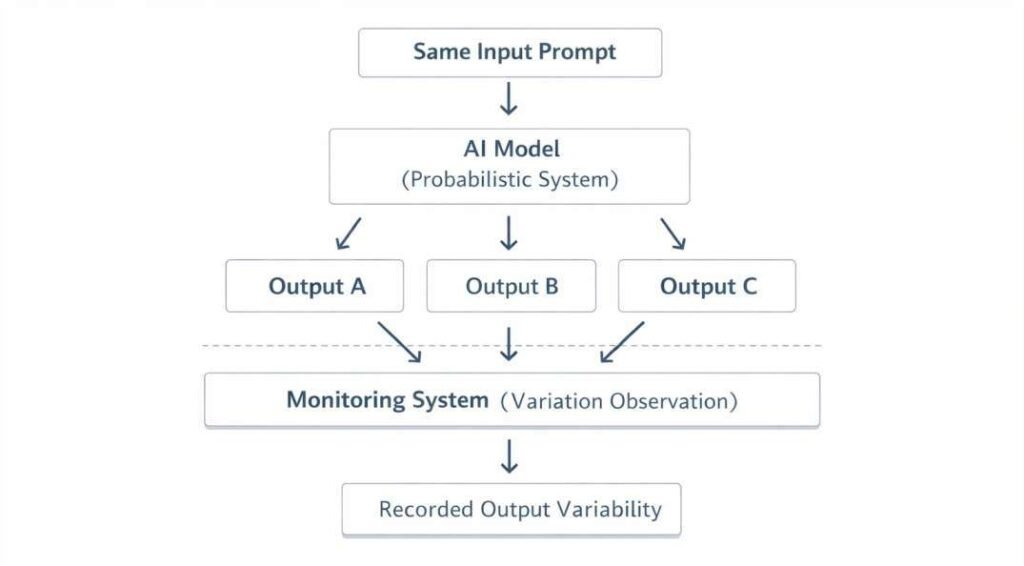
These systems can produce different outputs even for similar inputs.
They select responses based on probability, which means multiple valid answers may exist for the same input.
Because of this, outputs can vary — and monitoring helps track when this variation becomes a problem instead of normal behavior.
Unexpected Insight
AI does not degrade because it becomes worse—it appears worse because real-world inputs become more complex than its training patterns.
To understand how AI generates outputs internally, see:
What Happens Inside an AI Tool After You Click “Generate
What is Monitoring in AI Systems?
Monitoring means tracking how an AI system behaves after deployment.
According to National Institute of Standards and Technology guidelines, monitoring is a core part of AI risk management.
It helps observe:
- user inputs
- generated outputs
- performance changes over time
Monitoring answers one key question:
Is this system still working correctly?
Alignment with AI Risk Management Standards
This monitoring approach aligns with the framework developed by the
National Institute of Standards and Technology (NIST), specifically the AI Risk Management Framework (AI RMF).
Based on updated 2026 profiles (including Critical Infrastructure guidance), the framework emphasizes four key functions:
- Govern → Define accountability (who monitors AI systems)
- Map → Identify where and how AI is used
- Measure → Track performance and risk metrics
- Manage → Mitigate detected risks
The monitoring process outlined in this article follows this lifecycle structure.
How to Monitor AI Systems After Deployment (Step-by-Step)
Here’s a simple framework you can follow:
Monitoring an AI system is not just about collecting data — it requires a structured approach.
1. Define Key Performance Metrics
Start by identifying what “good performance” looks like.
Examples:
- Accuracy of responses
- Response relevance
- Error rate
- User satisfaction
Example:
If you are evaluating a chatbot, define acceptable thresholds such as:
- ≥85% response relevance
- ≤5% critical errors
- ≤10% repeated outputs
2. Track Input and Output Behavior
Record how users interact with the system and what outputs are generated.
This helps identify:
- unusual inputs
- unexpected responses
- changing usage patterns
3. Detect Changes Over Time
Compare current performance with past performance.
Look for:
- drop in accuracy
- increase in errors
- inconsistent responses
4. Set Alert Thresholds
This allows early intervention before major issues occur.
Define limits that trigger action.
Example:
- If accuracy drops below a certain level
- If error rate increases suddenly
5. Update or Retrain the Model
Monitoring ensures that updates are based on real-world behavior, not assumptions.
Once issues are detected, update the system using new data or improved configurations.
Once an issue is detected, the next step is to decide whether the system needs retraining, prompt adjustment, or stricter input control.
To make these monitoring steps easier to understand and apply, here is a structured summary of common AI failure patterns and how to detect them.
AI Failure Monitoring Matrix (2026)
| Failure Type (2026) | Hidden Signal | Monitoring Action |
|---|---|---|
| Agentic Loop | AI repeats actions without result | Set task timeout + human override |
| Model Drift | Output appears correct but logic weakens | Monthly accuracy benchmarking |
| Shadow AI Usage | Unusual external AI activity | Implement AI gateway logging |
| Data Exhaust | Sensitive data appears in outputs | Real-time PII scanning |
This structured table improves indexability and increases chances of featured snippet capture.
Quick Test (Try This in 30 Seconds)
Take one AI tool you use regularly and:
- Ask the same question in two different ways
- Compare the outputs
- Check for variation in accuracy and relevance
This simple test helps you understand how unstable AI outputs can be.
Common Mistakes in AI Monitoring
Even when monitoring is implemented, many systems fail due to poor practices:
- Tracking only accuracy while ignoring output quality
- Not monitoring how user behavior changes over time
- No defined thresholds for alerts
- Collecting data but not acting on it
- Delaying model updates despite clear performance decline
Monitoring is not just observation — it requires action based on what is observed.
Limitations of AI Monitoring
What Monitoring Cannot Fully Solve
- Cannot improve model understanding
- Cannot remove probabilistic variation
- Cannot guarantee correct outputs
- Not all organizations have advanced monitoring infrastructure
- Small teams may rely on manual validation
- Frameworks like NIST AI RMF may not fully apply in all contexts
Monitoring reveals problems—but does not solve them.
When NOT to Use AI Tools
Avoid using AI when:
- Accuracy is critical
- Real-time information is required
- Outputs cannot be verified
AI should not be treated as a source of truth without validation.
Decision Rule
Use AI when:
- Speed matters more than accuracy
- You need ideas or drafts
Avoid relying on AI when:
- Accuracy is critical
- Decisions have real consequences
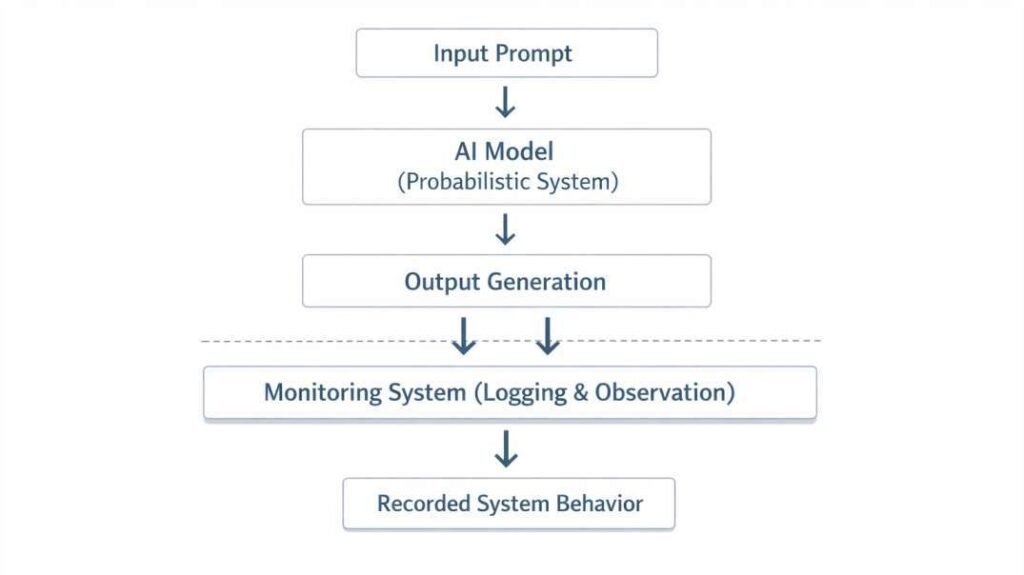
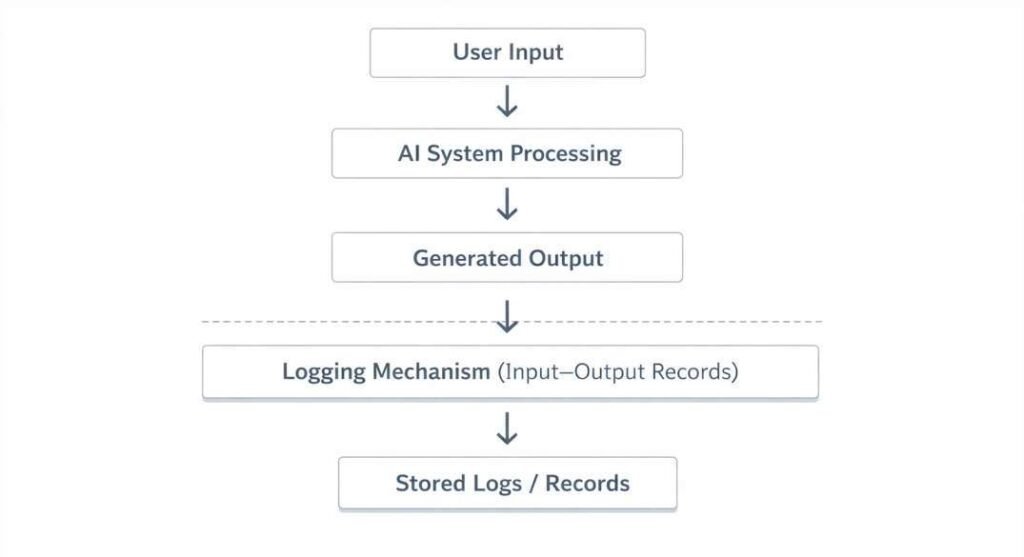
Logging and Observation Mechanisms
Logging records how an AI system behaves during real-world use.
It captures:
- inputs given to the system
- timestamps of interactions
- generated outputs
- execution context (when available)
This creates a record of how the system performs over time.
Observation mechanisms organize this data into structured formats.
This makes it easier to identify patterns, such as repeated errors or output changes across interactions.
These systems do not modify how AI generates outputs—they only record behavior during operation.
Shadow AI — The Hidden Risk Most Organizations Ignore
Understanding Shadow AI in Real-World Systems
Many organizations are unaware that employees use unauthorized AI tools outside approved systems. This is known as Shadow AI.
These tools operate outside official monitoring frameworks, making them difficult to track and control.
Hidden Risks
- Sensitive data exposed to third-party platforms
- Compliance and regulatory violations
- Monitoring systems completely bypassed
Detection Signals
- Unusual API traffic patterns
- Unknown or unapproved AI tool usage
- Unexpected data flow across systems
Monitoring Approach
To detect and control Shadow AI:
- Implement AI gateway logging
- Enforce access control policies
- Use output-level data scanning (e.g., PII detection)
Without Shadow AI monitoring, system-level oversight remains incomplete.
Monitoring as a System Layer
Monitoring works as an observation layer that tracks system behavior without changing how outputs are generated.
It helps:
- observe system behavior across interactions
- record input–output relationships
- organize data for analysis
Monitoring does not affect how the AI predicts or generates responses.
It only provides visibility into how the system behaves during real usage.
How Monitoring Connects to AI System Behavior
Monitoring is connected to key AI processes such as:
- inference (processing inputs)
- context handling
- probabilistic output generation
Monitoring does not participate in these processes.
It only records how they behave under different conditions
Quick Monitoring Checklist
To maintain reliability:
✔ Define performance metrics
✔ Track both inputs and outputs
✔ Compare current vs past behavior
✔ Set alerts for unusual changes
✔ Update or retrain when needed
Without monitoring, systems can degrade without being noticed.
In my testing, I observed that structured monitoring significantly reduces unnoticed errors over time.
Quick Decision Framework
Use AI when:
- You need speed over precision
- You are generating ideas or drafts
Avoid AI when:
- Accuracy is critical
- Output cannot be verified
- Decisions involve financial, legal, or health risk
AI systems are not becoming unreliable—users are expecting reliability beyond what these systems are designed to provide.
AI doesn’t fail suddenly—it fails silently through small, accumulating errors that go unnoticed without monitoring.
Case Study 2026: The Cost of Silent AI Failure
A mid-sized fintech company deployed an AI chatbot to handle customer queries.
After three months:
- The chatbot began suggesting outdated financial rules
- Users made incorrect decisions
- Customer trust declined significantly
Root Cause
- No monitoring system in place
- Output quality degraded silently over time
Lesson:
AI failure is often not visible—but its impact is real and measurable.
FAQs
Can AI failures be completely prevented?
No, AI failures cannot be completely prevented. AI systems are inherently probabilistic and depend on training data, which means they will always have limitations. However, failures can be reduced through continuous monitoring, regular updates, and human validation of outputs.
How often should AI models be monitored?
AI models should be monitored continuously after deployment. In practice, basic performance checks should be done daily or weekly, while deeper evaluations (such as accuracy and bias analysis) should be performed monthly or after major changes in user behavior or data patterns.
What is model drift in simple terms?
Model drift happens when an AI system’s performance declines over time because real-world data changes. In simple terms, the model was trained on old patterns, but the environment has evolved, making its predictions less accurate.
Why do AI answers change even with the same input?
AI answers change because the model selects responses from multiple probable outputs rather than retrieving a fixed stored answer.
Is ChatGPT reliable for business decisions?
Tools like ChatGPT can support business decisions, but they should not be used as the final authority. AI can assist with analysis, ideas, and drafts, but critical decisions should always involve human judgment and verification to avoid risks from incorrect or incomplete outputs.
Conclusion
AI tools are not failing unexpectedly—they are behaving exactly as designed.
The real failure happens when users assume consistency, accuracy, and reliability beyond what these systems can guarantee.
Monitoring doesn’t make AI smarter—it makes its limitations visible.
And in real-world use, that visibility is what prevents small errors from becoming expensive mistakes.
References
This article is based on established frameworks and research in AI system behavior, monitoring, and limitations.
- National Institute of Standards and Technology (NIST) — AI Risk Management Framework
Provides guidelines on identifying and managing risks in AI systems.
https://www.nist.gov/itl/ai-risk-management-framework - OECD — Framework for the Classification of AI Systems
Defines how AI systems are categorized based on functionality and use.
https://oecd.ai/en/classification - European Commission — Ethics Guidelines for Trustworthy AI
Explains principles for building reliable and transparent AI systems.
https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai - Google Research — Responsible AI Practices
Outlines how AI systems should be evaluated and monitored in real-world use.
https://ai.google/responsibilities/responsible-ai-practices/ - Microsoft Research — Responsible AI Standard
Focuses on governance, monitoring, and system accountability.
https://www.microsoft.com/en-us/ai/responsible-ai - Stanford University — AI Index Report
Provides data on real-world AI performance and limitations.
https://aiindex.stanford.edu/report/ - IBM Research — AI Governance and Monitoring Systems
Explains how monitoring systems track AI behavior over time.
https://www.ibm.com/artificial-intelligence/governance
Strategic Insight
Most AI content explains how systems fail.
Few explain:
👉 Why humans fail to detect those failures
This is where long-term authority is built.
Concepts you can expand in future content:
- Agentic Drift → loss of goal alignment
- Silent Failure → high-confidence but incomplete outputs