
Introduction
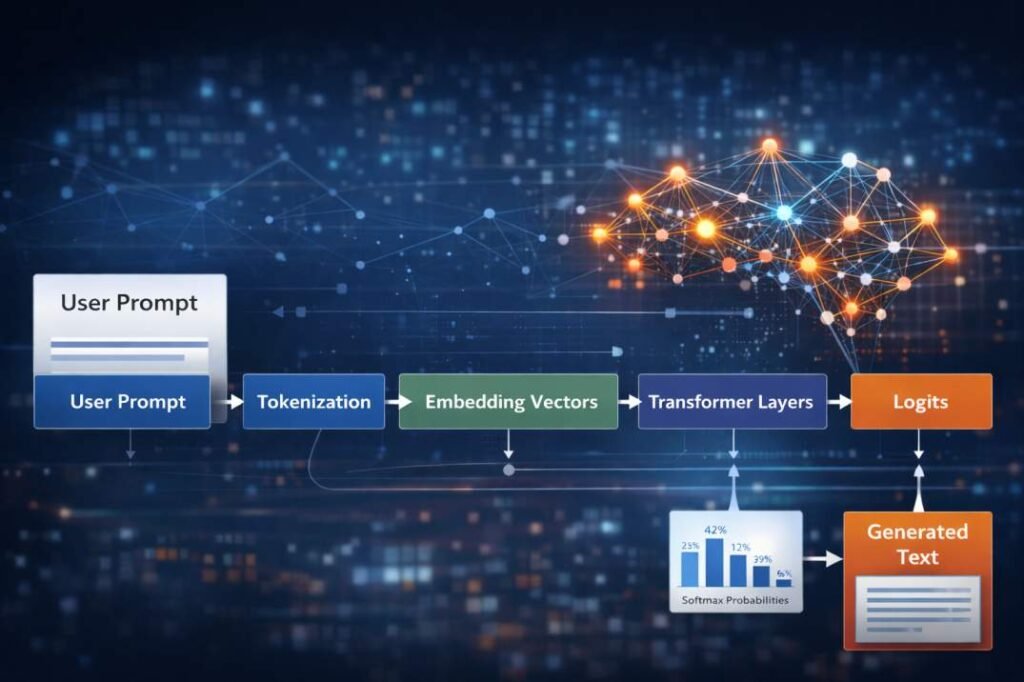
The AI text generation process begins when a user selects the “Generate” button in an AI tool interface, the request initiates a structured computational workflow inside the system. The interface action itself does not directly produce text output. Instead, it triggers a sequence of internal operations that process the submitted prompt through the model’s inference architecture.
AI text generation systems are commonly deployed in conversational interfaces, content-generation tools, research assistants, and automated language processing systems. In these systems, a user prompt triggers a sequence of internal computational operations that transform the input text into a generated response.
Definition: AI Text Generation Process
The AI text generation process refers to the sequence of computational transformations through which a trained language model converts an input prompt into generated text during inference. During this process, input text is converted into tokens, processed through neural network layers, evaluated through probability distributions, and assembled into output text.
AI systems process inputs using probabilistic prediction mechanisms rather than deterministic instruction execution, a structural distinction often discussed when comparing AI tools and traditional software systems.
During this process, the user’s text input is converted into numerical representations and passed through a series of computational transformations. These transformations occur inside the neural network model that powers the tool.
The process described in this article focuses on the model inference pipeline, which refers to the stage in which a trained AI model processes new input data to produce output predictions.
AI text generation systems typically process requests through a sequence of computational stages that together form the internal processing pipeline of an AI tool. Each stage transforms the internal representation of the input before passing the resulting data structure to the next stage in the pipeline. The numbered sections below describe these stages in the order they commonly occur during inference.
Where This Process Occurs in an AI System
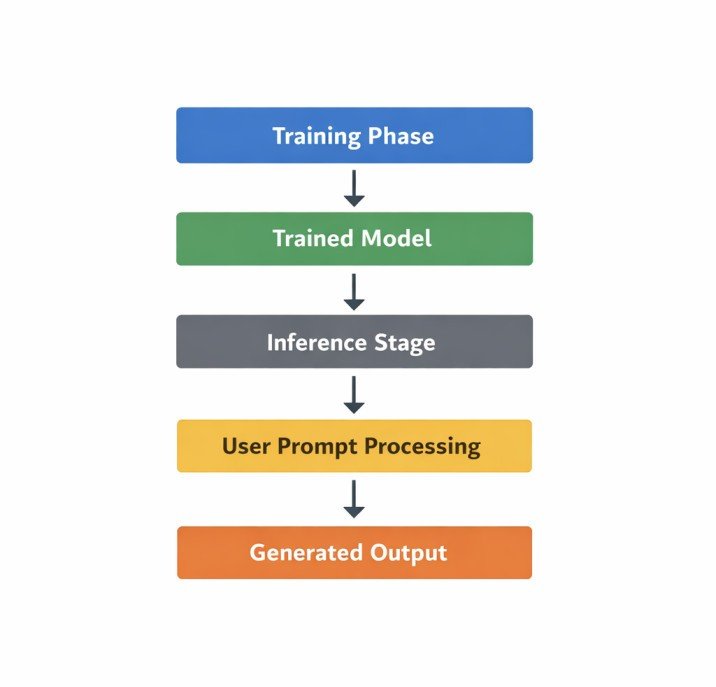
AI systems typically operate across multiple lifecycle stages that together form the operational framework of modern AI tools.
One stage involves training the model using large datasets in order to adjust the internal parameters of the neural network.
The process described in this article occurs after training has been completed.
This stage is commonly referred to as model inference, which is the operational phase in which a trained model processes new input data.
During inference, the model does not modify its internal parameters.
Instead, it applies the learned parameters from training to compute predictions based on incoming input.
The stages described in the following sections represent the sequence of computational transformations that occur during inference when an AI system processes a prompt submitted through an interface.
The inference pipeline functions as a sequence of transformations in which each stage modifies the internal representation of the prompt before passing it to the next stage. The stages described below represent the ordered operations commonly used in AI text generation systems during inference.
AI Text Generation Process: Inference Pipeline
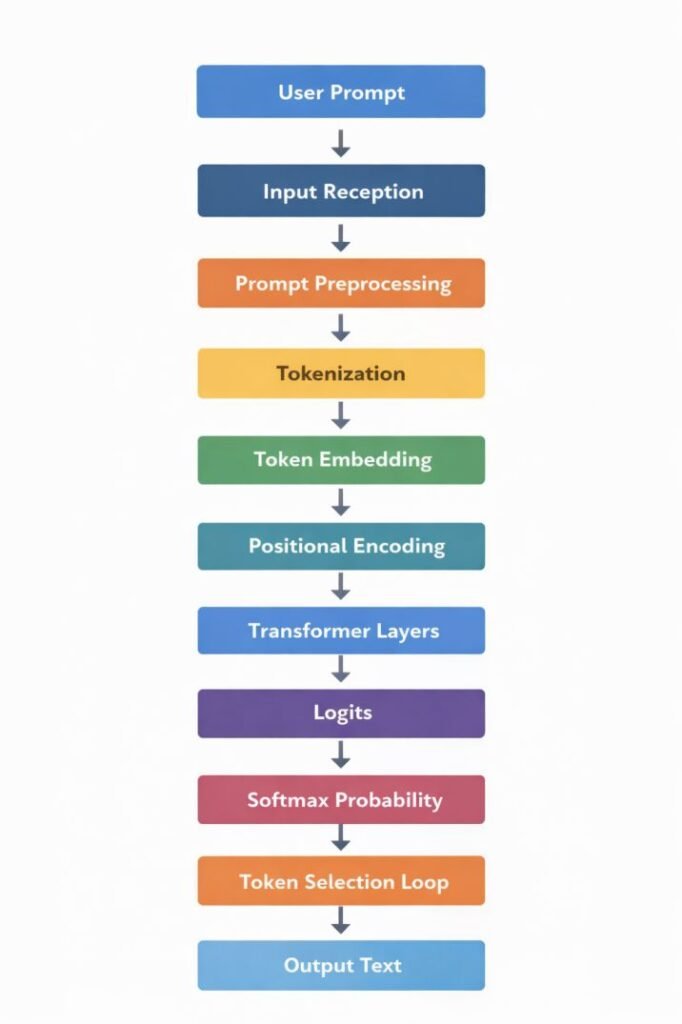
User Prompt
↓
Input Reception
↓
Prompt Preprocessing
↓
Tokenization
↓
Token Embedding
↓
Positional Encoding
↓
Transformer Processing Layers
↓
Logit Generation
↓
Probability Distribution (Softmax)
↓
Token Selection Loop
↓
Output Text
Key Terms Used in the Pipeline
Several technical terms are referenced throughout the inference pipeline.
Token
A computational unit representing a fragment of text that the model processes internally.
Embedding Vector
A numerical representation assigned to each token that allows the model to perform mathematical operations on text data.
Transformer Layer
A neural network layer responsible for computing contextual relationships between tokens in a sequence.
Logits
Unnormalized numerical scores assigned to possible next tokens before probability normalization.
Softmax
A mathematical function used to convert logit scores into a probability distribution.
1. Input Reception
The process begins when the interface sends the submitted prompt to the system’s backend processing environment.
At this stage, the user’s text input becomes part of a structured request transmitted from the client interface to the server infrastructure where the AI model is deployed.
The request generally includes:
- the prompt text submitted by the user
- configuration parameters associated with the generation request
- session identifiers used for request tracking
- model routing information specifying which model instance will process the request
This data is packaged as a request payload and transmitted to the server responsible for handling inference operations.
Within the server environment, the system performs initial validation checks to ensure that the request format conforms to the expected structure required by the processing pipeline.
Once validated, the prompt is forwarded to the preprocessing stage.
2. Prompt Preprocessing
Before the input text can be processed by the neural network, the system performs several preprocessing operations.
Neural networks do not directly process raw human-readable text. Instead, the input must first be standardized and prepared for conversion into numerical representations.
Preprocessing operations commonly include:
- normalization of character encoding
- removal or conversion of unsupported symbols
- sequence length verification
- formatting adjustments required by the model’s tokenizer
The goal of preprocessing is to ensure that the prompt text is structured in a form compatible with the tokenization system used by the model.
During this stage, the system may also enforce sequence length limits defined by the model architecture. If the prompt exceeds the maximum token capacity, the input may be truncated or segmented according to predefined rules.
After preprocessing is completed, the standardized text sequence proceeds to the tokenization stage.
3. Tokenization
After preprocessing standardizes the prompt text, the system converts the input into smaller computational units through tokenization.
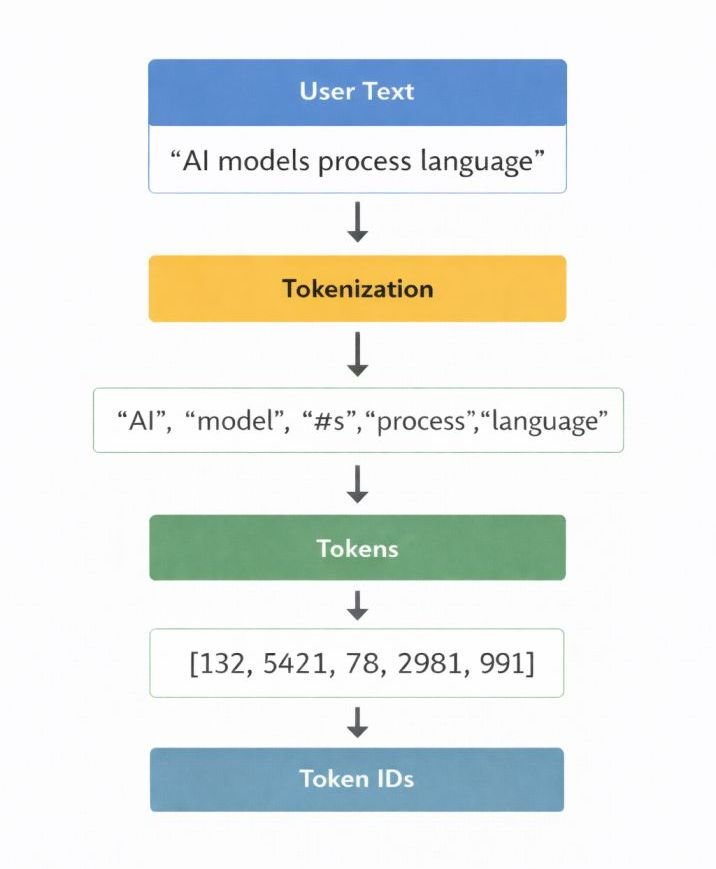
Tokenization is the process in which the input text is divided into smaller computational units known as tokens.
Tokens represent the fundamental units that the model processes internally. Depending on the tokenizer design used by the model, tokens may correspond to:
- complete words
- partial word segments
- characters
- punctuation symbols
For example, a word such as processing may be represented as multiple subword tokens depending on the tokenizer vocabulary.
After the text is segmented into tokens, each token is mapped to a unique numerical identifier defined within the model’s vocabulary table.
This mapping converts the text sequence into a numerical sequence.
Example transformation:
User Prompt
↓
Tokenized Text Units
↓
Token IDs
At this stage, the system has transformed the human-readable prompt into a structured sequence of numerical identifiers. These identifiers form the input that will be passed into the neural network.
However, token identifiers alone do not contain sufficient information for the neural network to perform computations. Therefore, the token IDs must first be converted into vector representations.
4. Token Embedding
Once the prompt has been segmented into tokens and mapped to token identifiers, the system converts these identifiers into embedding vectors.
Embedding vectors are numerical arrays that represent tokens within a high-dimensional vector space. Each token in the model’s vocabulary is associated with a learned vector stored in the model’s embedding matrix.
When the token ID sequence is passed to the embedding layer, each ID is replaced with its corresponding vector representation.
This transformation converts discrete token identifiers into continuous numerical representations that can be processed by neural network layers.
Embedding vectors encode patterns learned during training, allowing the model to represent tokens as points in a structured numerical space.
In this space, tokens that appear in similar contexts during training may occupy nearby positions in the vector space.
The resulting sequence of embedding vectors forms the initial numerical representation of the prompt within the model.
However, this representation does not yet contain information about the order of tokens within the sequence.
The concept of distributed word representations used in embedding spaces has been widely studied in neural language modeling research, including work on word embeddings and distributed representations (Mikolov et al., 2013).
5. Positional Encoding
Transformer-based models process tokens in parallel rather than sequentially. Because of this parallel processing architecture, the model requires an additional mechanism to represent the position of each token within the input sequence.
This information is introduced through positional encoding.
Positional encoding generates numerical signals that represent the position index of each token in the sequence.
These positional signals are combined with the token embedding vectors to produce a final input representation.
The combination process ensures that the model receives information about:
- token identity (from embeddings)
- token position (from positional encoding)
The combined embedding and positional signals form the structured input representation that enters the model’s transformer processing layers.
6. Transformer Processing Layers
Transformer layers are a neural network architecture introduced in the research paper Attention Is All You Need (Vaswani et al., 2017). These layers compute contextual relationships between tokens using attention mechanisms and feedforward neural networks.
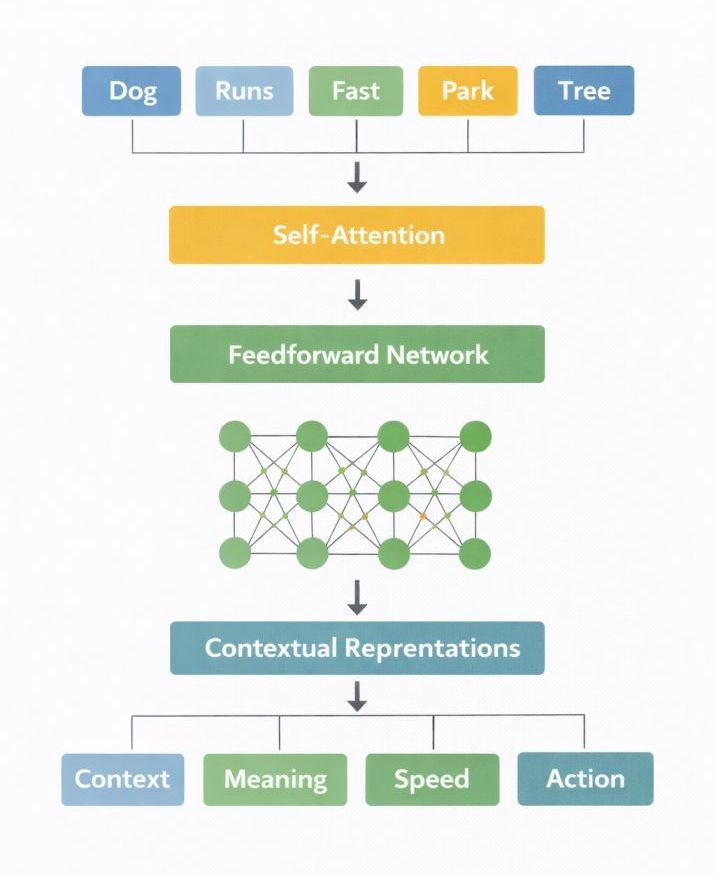
After the input representation is prepared, the data is passed through the model’s stacked transformer layers.
Transformer layers perform the primary computational operations of the model and represent one of the central architectural components used in modern AI systems.
Each layer typically contains several internal components, including:
- multi-head attention mechanisms
- feedforward neural networks
- normalization operations
- residual connections
During this stage, the model repeatedly transforms the token representations using learned weight matrices.
One of the central mechanisms within transformer layers is the attention mechanism. This mechanism calculates relationships between tokens in the sequence by computing weighted interactions between token representations.
Through these calculations, each token representation can incorporate contextual information from other tokens in the input sequence.
As the token representations pass through successive transformer layers, they are progressively transformed into increasingly complex internal representations.
These representations encode contextual patterns learned during the model’s training process.
The final internal representation produced by the transformer layers becomes the input to the model’s output projection stage, where numerical scores for possible next tokens are computed.
7. Logit Generation
After the transformer layers produce contextual representations, the system computes prediction scores known as logits. After the final transformer layer completes its computations, the model generates a numerical vector known as logits.
Logits are real-valued scores assigned to every token within the model’s vocabulary.
These scores are produced by applying a linear transformation to the final hidden representation generated by the transformer layers.
Each value in the logit vector represents the model’s internal scoring of a possible next token.
At this stage, the values are not probabilities. They are unnormalized scores representing relative preferences among tokens.
Higher logit values correspond to tokens that the model assigns greater internal weight during prediction.
To interpret these scores as probabilities, a normalization operation is applied.
8. Probability Distribution Formation
The logit scores must then be normalized to represent probabilities for the next token. The normalization process converts logits into probabilities using a mathematical function commonly known as softmax.
The softmax function transforms the vector of logit scores into a probability distribution across the vocabulary.
The resulting probability distribution has the following properties:
- each token receives a probability value
- all probability values sum to 1
- tokens with larger logits receive larger probabilities
This probability distribution represents the model’s calculated likelihoods for the next token in the sequence.
The system then uses this probability distribution to determine which token will be selected for the output sequence.
9. Token Selection
Once probabilities are computed, the system selects the next token from the distribution.
Token selection determines which token will be appended to the generated output sequence.
Different selection strategies may be used depending on the configuration of the generation process. These strategies operate on the probability distribution produced by the softmax operation.
After a token is selected, it is appended to the generated token sequence.
The updated sequence is then fed back into the model as the new input context.
The model repeats the prediction process to generate the next token.
This repeated prediction process forms an autoregressive generation loop in which the model generates one token at a time.
The loop continues until a predefined stopping condition is reached.
Autoregressive Generation Loop
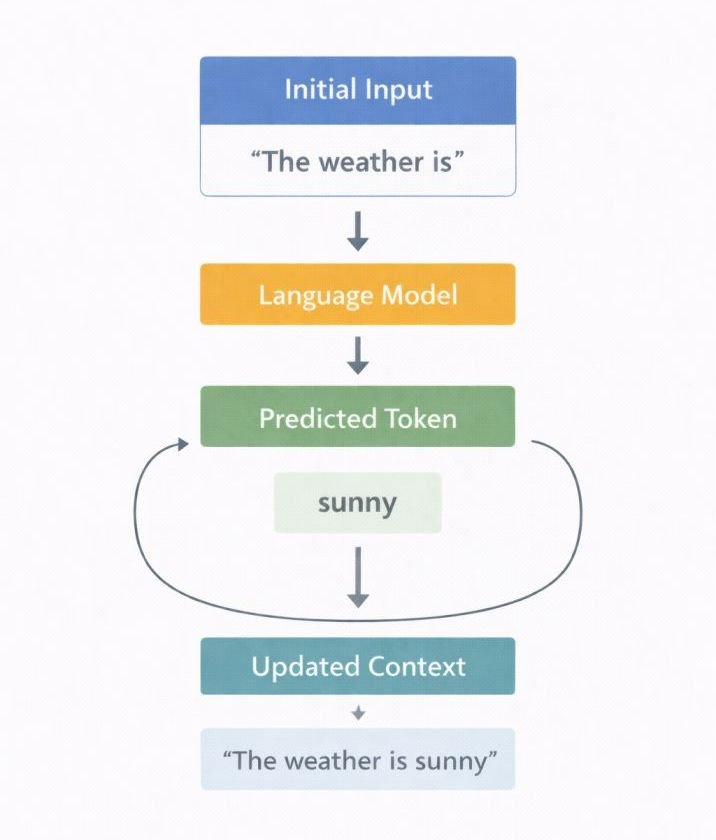
Input Context
↓
Model Computes Probabilities
↓
Next Token Selected
↓
Token Added to Sequence
↓
Updated Context
↓
Prediction Repeats
10. Output Assembly
After the token generation loop terminates, the system reconstructs readable text from the generated token sequence. The model produces a final sequence of token identifiers that must be converted back into readable text.
These tokens must then be converted back into readable text.
During this stage, the system performs a reverse transformation process:
- token IDs are mapped back to their corresponding token strings
- token fragments are merged according to the tokenizer’s decoding rules
- spacing and punctuation are reconstructed
After these transformations are completed, the resulting text sequence is returned to the interface and displayed to the user.
Pipeline Recap Table
| Pipeline Stage | Internal Operation |
|---|---|
| Input reception | Prompt transmitted to server environment |
| Prompt preprocessing | Text normalized and validated |
| Tokenization | Text segmented into tokens |
| Token embedding | Tokens converted into vector representations |
| Positional encoding | Token order information introduced |
| Transformer layers | Contextual relationships computed |
| Logit generation | Raw scores assigned to candidate tokens |
| Probability formation | Softmax converts logits into probabilities |
| Token selection | Next token chosen from probability distribution |
| Output assembly | Tokens converted back into readable text |
AI Text Generation Process Overview
AI text generation systems transform input prompts through a sequence of computational representations:
Prompt
→ Tokens
→ Embedding Vectors
→ Contextual Representations
→ Logits
→ Probability Distribution
→ Generated Tokens
→ Output Text
The computational stages described in this pipeline represent the internal operations through which transformer-based language models process text during inference. Although these transformations occur within milliseconds inside server infrastructure, they involve multiple layers of numerical computation that convert text into vector representations, evaluate token probabilities, and iteratively assemble output sequences.
Summary
When the “Generate” command is activated, the AI system processes the submitted prompt through a structured inference pipeline composed of multiple computational stages.
During this process, the original text input is progressively transformed through several internal representations. The prompt is first converted into tokens, which are then mapped into numerical vectors that can be processed by neural network layers.
Within the model, these vector representations pass through transformer layers where contextual relationships between tokens are computed. The resulting internal representations are then converted into numerical scores known as logits, which are normalized into probability distributions used to select the next output token.
Through repeated iterations of this prediction cycle, the system constructs a sequence of tokens that is subsequently decoded into readable text and returned to the interface.
In simplified form, the transformation pipeline can be represented as:
Prompt
↓
Tokens
↓
Embedding Vectors
↓
Contextual Representations
↓
Logits
↓
Probability Distribution
↓
Generated Token Sequence
↓
Output Text
The visible response produced by the AI tool therefore represents the result of successive numerical transformations applied to encoded input representations within the model’s inference architecture.
Frequently Asked Questions
What is tokenization in the AI text generation process?
Tokenization is the stage in which input text is divided into smaller computational units known as tokens. These tokens may represent words, subword segments, characters, or punctuation symbols depending on the tokenizer design used by the model.
What role do transformer layers play in AI text generation?
Transformer layers compute contextual relationships between tokens using attention mechanisms and feedforward neural networks. Through repeated transformations of token representations, these layers produce contextual embeddings that enable the model to evaluate possible next tokens during generation.
How are probabilities calculated during token prediction?
During token prediction, the model produces numerical scores called logits for each token in the vocabulary. These scores are converted into probabilities using the softmax function, which normalizes the logits into a probability distribution that sums to one.
What is the token selection loop in AI text generation?
The token selection loop is the iterative stage in which the model repeatedly predicts the next token based on the previously generated sequence. After each token is selected, it is appended to the sequence and used as part of the context for the next prediction step.
What is model inference in AI systems?
Model inference refers to the stage in which a trained AI model processes new input data to generate predictions or outputs. During inference, the model applies parameters learned during training but does not modify those parameters.
References
Attention Is All You Need
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017).
Attention Is All You Need.
Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS).
https://arxiv.org/abs/1706.03762
Speech and Language Processing
Jurafsky, D., & Martin, J. H. (2023 draft).
Speech and Language Processing (3rd Edition Draft).
Stanford University.
https://web.stanford.edu/~jurafsky/slp3/
Neural Probabilistic Language Model
Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003).
A Neural Probabilistic Language Model.
Journal of Machine Learning Research.
https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
Distributed Representations of Words and Phrases
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013).
Distributed Representations of Words and Phrases and their Compositionality.
Advances in Neural Information Processing Systems (NeurIPS).
https://arxiv.org/abs/1310.4546
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2018).
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
https://arxiv.org/abs/1810.04805
Google Research
Google Research.
Text-to-Text Transfer Transformer (T5) model architecture documentation.
https://arxiv.org/abs/1910.10683
OpenAI
OpenAI.
Language Models are Few-Shot Learners.
Brown, T. et al. (2020).
https://arxiv.org/abs/2005.14165
DeepLearning.AI
DeepLearning.AI.
Transformer architecture overview and attention mechanisms.
https://www.deeplearning.ai/resources/transformer-model/