

Introduction
Why AI tools give different answers to the same question is a behavior frequently observed in modern artificial intelligence systems. When identical prompts are submitted multiple times, the generated responses may vary even though the input remains unchanged.
This variation occurs because many AI generation systems operate using probabilistic prediction mechanisms rather than deterministic rule execution. Instead of retrieving a fixed response from a predefined database, the model evaluates multiple possible output sequences and assigns probability values to candidate tokens during the inference process.
This article examines the computational mechanisms that produce response variability in modern AI systems, focusing on token prediction, probability distributions, and sampling methods used in transformer-based language models.
The probabilistic approach used in modern AI generation systems developed through several stages of research in machine learning and natural language processing. One significant milestone occurred in June 2017, when researchers introduced the transformer architecture in the paper Attention Is All You Need. This architecture established the computational structure used by many modern language models for processing sequential text data.
Within transformer-based models, the generation of text occurs through a sequence of transformations that convert an input prompt into internal numerical representations. These transformations are part of the broader system architecture described in Core Structural Components of AI Tools. These representations are then used to calculate probabilities for potential output tokens.
Because the model evaluates many possible continuations of a prompt rather than retrieving a single stored response, several valid output sequences may exist within the model’s probability space. When the generation process is repeated, the system may select different token sequences that satisfy the probability conditions produced during inference.
Understanding why AI tools give different answers therefore requires examining how input prompts are processed, transformed into internal representations, and converted into generated output sequences. A broader overview of how modern AI systems process prompts and generate outputs is presented in How AI Tools Work: Internal Architecture and Generation Processes.
What Is Response Variability in AI Systems
Response variability refers to the condition in which an AI system produces different outputs when processing identical or highly similar input prompts.
In probabilistic generation systems, the model does not compute a single predetermined response. This differs from deterministic behavior typically observed in traditional software systems, discussed in AI Tools vs Traditional Software. Instead, it calculates probability scores for many candidate tokens that could appear next in a sequence.
Response variability arises from several interacting mechanisms within the generation process, including:
- probabilistic token prediction
- stochastic sampling mechanisms
- contextual interpretation of token sequences
- model configuration parameters
- sequential token generation during autoregressive inference
These mechanisms collectively create a system in which multiple token sequences may represent valid continuations of the same prompt.
Deterministic vs Probabilistic Systems
Traditional rule-based software systems often operate deterministically.
In deterministic systems, identical input conditions produce identical outputs because the system follows predefined logical rules.
Modern language models operate probabilistically.
Instead of executing fixed rules, they calculate probability distributions over possible outputs and select tokens based on those probabilities.
Because multiple tokens may satisfy the probability conditions, several valid output sequences may exist for the same input prompt.
Historical Development of Probabilistic Language Models
The concept of probabilistic language generation has developed over several decades within computational linguistics and machine learning research.
Early statistical language models appeared in the 1990s, when researchers began applying probabilistic methods to predict word sequences using n-gram models. These models estimated the probability of a word based on the preceding words in a sequence.
During the 2010s, neural network–based language models replaced many traditional statistical methods. Recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) were used to model sequential text data by learning patterns across word sequences.
A major shift occurred in 2017 with the introduction of the transformer architecture. Transformers introduced an attention-based mechanism that allowed models to evaluate relationships between tokens across an entire sequence rather than processing text strictly in order.
This architecture enabled the development of large-scale language models capable of predicting tokens within complex textual contexts. These models calculate probability distributions across large vocabularies of tokens, allowing multiple possible continuations for a given input sequence.
As a result, probabilistic output generation became a central characteristic of modern AI systems used for language generation.
Where Response Variation Occurs in AI Systems
Response variation occurs during the model inference stage, which is the operational phase in which a trained AI model processes new input data. The internal sequence of events during inference is examined in What Happens Inside an AI Tool After You Click “Generate”. This probabilistic inference process explains why response variation may occur when identical prompts are processed multiple times.
During inference, the model applies the patterns learned during training to generate predictions for new prompts.
The process generally follows these stages:
- The system receives the user’s prompt.
- The prompt is converted into token representations.
- Token representations are transformed into embedding vectors.
- The model processes these vectors through neural network layers.
- Probability distributions are computed for candidate output tokens.
- Tokens are selected sequentially to construct the generated response.
Because the model evaluates multiple candidate tokens during each prediction step, several output sequences may satisfy the probability conditions generated by the model.
The variation observed in AI responses therefore originates from the probabilistic prediction process used during inference.
AI Prompt Processing Pipeline

Before probability calculations occur, the prompt undergoes several internal transformations within the model. The computational stages involved in AI text generation are examined in greater detail in AI generation architecture.
A simplified representation of this process is shown below:
Prompt
↓
Tokenization
↓
Embedding Vectors
↓
Transformer Processing Layers
↓
Probability Distribution
↓
Token Sampling
↓
Generated Output
Each stage performs a specific computational function.
Tokenization in AI Language Models
Tokenization converts the input prompt into discrete units called tokens. Tokens may represent words, subwords, or character sequences depending on the tokenization method used by the model.
For example, the sentence:
“AI systems process language”
may be converted into tokens such as:
[AI] [systems] [process] [language]
This formatting illustrates how a sentence may be segmented into discrete tokens during the tokenization process.
Embedding Representations in AI Models
After tokenization, each token is converted into a numerical vector representation known as an embedding.
Embedding vectors allow tokens to be represented as points within a high-dimensional mathematical space. In this representation, tokens that appear in similar contexts may occupy nearby positions within the embedding space.
These numerical representations allow neural network layers to compute relationships between tokens.
Transformer Processing and Context Representation
Within transformer-based models, embedding vectors pass through multiple computational layers designed to capture contextual relationships between tokens.
Each layer typically contains two major components:
- Self-attention mechanisms
- Feedforward neural networks
Self-attention mechanisms evaluate relationships between tokens in the sequence, allowing the model to determine which tokens influence each other.
For example, consider the sentence:
“The scientist analyzed the data because it was incomplete.”
The model may identify that the word “it” refers to “data” rather than “scientist.”
The feedforward layers then transform the representations produced by the attention mechanism into updated vector states that capture contextual meaning.
These transformations are repeated across multiple layers, allowing the model to construct increasingly complex representations of the input sequence.
Probabilistic Token Prediction
After processing the input sequence through transformer layers, the model produces a numerical vector representing the current context.
This vector is used to compute logits, which are unnormalized numerical scores assigned to each possible token in the model’s vocabulary.
These logits are then converted into probabilities using a mathematical function known as the softmax function, which normalizes the scores so that the resulting probabilities sum to one.
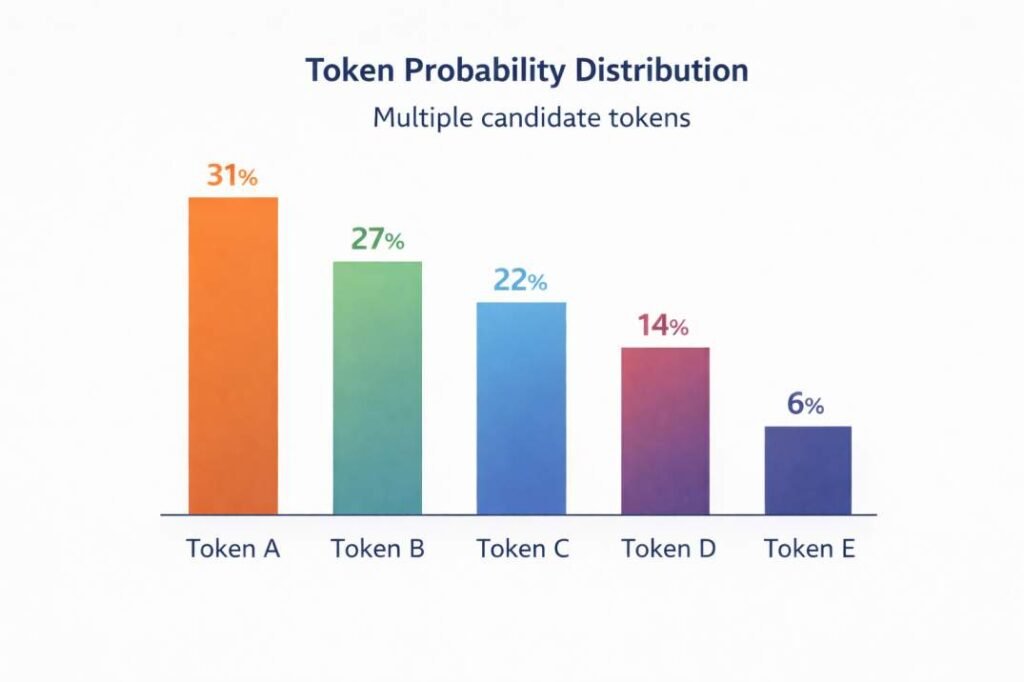
The resulting probability distribution may resemble the following example:
| Candidate Token | Logit Score | Probability |
|---|---|---|
| Token A | 2.10 | 0.31 |
| Token B | 1.95 | 0.27 |
| Token C | 1.70 | 0.22 |
| Token D | 1.20 | 0.14 |
| Token E | 0.75 | 0.06 |
These probability values represent the model’s estimated likelihood of each token appearing next in the sequence.
Softmax Normalization
The logits produced by the model are converted into probabilities using the softmax function, which normalizes scores across the model’s vocabulary:
This function converts raw model scores into a normalized probability distribution across candidate tokens.
where:
- z_i represents the logit score of token i
- V represents the vocabulary size
The resulting probabilities indicate the relative likelihood of each token appearing next in the sequence.
Because multiple tokens may have similar probability values, several possible continuations of the sequence may exist.
Token Sampling Methods in AI Generation
To select the next token from the probability distribution, AI systems apply sampling mechanisms. Sampling methods determine how candidate tokens are selected from the probability distribution produced by the model.
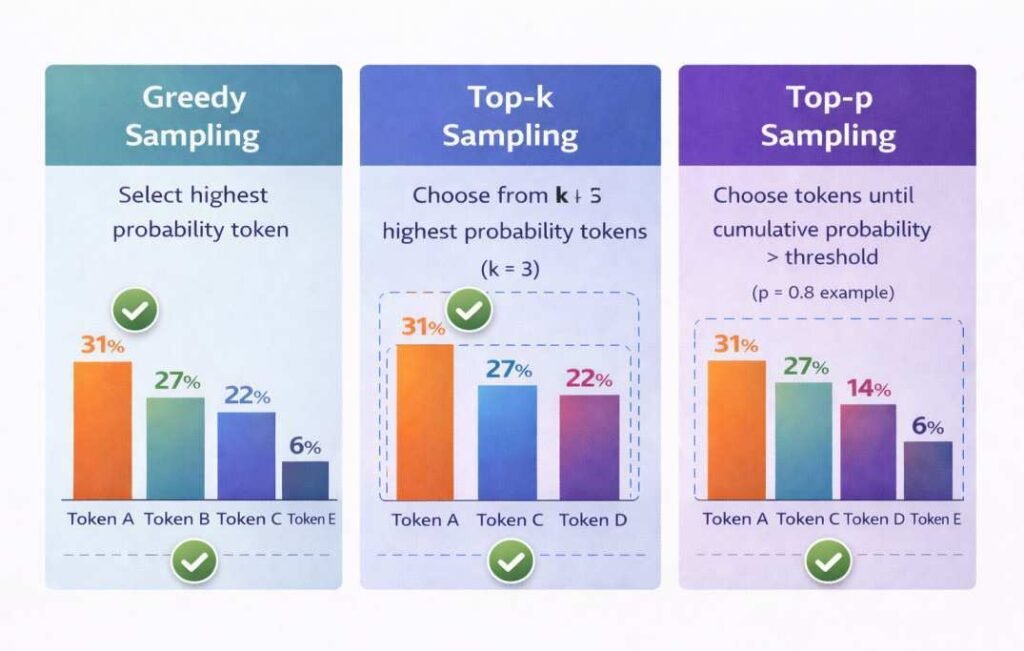
Greedy Selection
Greedy selection chooses the token with the highest probability value at each prediction step. Because the highest-probability token is consistently selected, this approach tends to produce more deterministic outputs.
Top-k Sampling
Top-k sampling limits token selection to the k most probable tokens in the probability distribution.
For example, if k = 5, only the five highest-probability tokens are eligible for selection during the generation step.
Top-p (Nucleus) Sampling
Top-p sampling, also called nucleus sampling, selects tokens from a subset whose cumulative probability exceeds a defined threshold.
This method allows the number of candidate tokens to vary depending on the probability distribution produced by the model.
Because these sampling mechanisms operate on probability distributions, different tokens may be selected during separate generation attempts.
How Context Influences AI Response Generation
AI models interpret prompts based on contextual representations created during transformer processing.
The representation of each token is influenced by its relationships with other tokens in the sequence.
For example, the meaning of the word bank may differ depending on whether the surrounding context refers to finance or geography.
When the model calculates probability distributions for the next token, it relies on the contextual representations generated during processing.
If several token sequences represent plausible continuations of the context, the probability distribution may contain multiple high-probability candidates.
This condition allows different token selections to occur during separate generation runs.
Configuration Parameters and AI Output Variation
AI generation systems often include configuration parameters that influence how probability distributions are used during token selection.
Common parameters include:
| Parameter | Role in Generation |
|---|---|
| Temperature | Controls randomness of token probability distribution |
| Top-k | Limits candidate tokens to the k highest probabilities |
| Top-p (nucleus sampling) | Selects tokens whose cumulative probability exceeds threshold p |
| Maximum tokens | Limits length of generated sequence |
These parameters influence how the probability distribution is sampled during generation and may affect response variability.
The temperature parameter modifies the distribution of probability values.
Lower temperature values produce sharper distributions, concentrating probability on a smaller set of tokens. Higher temperature values distribute probability more evenly across candidate tokens.
These adjustments can influence which tokens are selected during generation.
Autoregressive Generation and Response Variation
Many AI text generation systems use an autoregressive generation process.
In autoregressive generation, tokens are produced sequentially.
The generation process follows a repeating loop:
Input Prompt
↓
Model Predicts Next Token
↓
Token Selected
↓
Token Added to Context
↓
Model Predicts Next Token
Each newly generated token becomes part of the input context used to compute the next prediction. However, these generated tokens do not update the model’s training parameters, a distinction discussed in Why AI Tools Don’t Learn From Your Prompts.
If variation occurs early in the sequence, the updated context may alter subsequent probability calculations.
Over multiple prediction steps, these differences may accumulate and produce different final outputs.
Conceptual Example
Consider the prompt:
“Explain how AI models process language.”
When the prompt is processed by a language model, multiple valid continuations may exist within the probability distribution.
Two generated responses may begin differently:
Response A
AI models process language by converting text into tokens that are analyzed through neural network layers.
Response B
AI systems interpret language by transforming text into vector representations that capture contextual relationships between words.
Both responses represent valid continuations according to the probability distributions computed by the model.
Relationship Between Probability, Sampling, and Context
Response variability in AI systems emerges from the interaction of several computational mechanisms:
- probability distributions generated during token prediction
- sampling mechanisms used for token selection
- contextual representations produced by transformer layers
- sequential token generation during autoregressive inference
These mechanisms operate together during inference, creating a system in which multiple output sequences may represent valid responses to the same prompt.
Summary
The sections above describe the computational mechanisms that contribute to response variability in modern AI systems.
These mechanisms form part of the broader computational architecture used in modern AI systems, described in internal architecture of AI tools. Response variability is a structural characteristic of many modern AI generation systems that operate using probabilistic prediction mechanisms. Rather than retrieving a single predetermined response, language models evaluate probability distributions across many possible tokens during each prediction step. Multiple candidate tokens may satisfy the probability conditions calculated by the model.
During the inference process, several computational stages transform the input prompt into generated output. The prompt is first converted into token sequences through tokenization. These tokens are then represented as numerical vectors through embedding processes. Transformer processing layers analyze relationships between tokens and construct contextual representations of the sequence. Based on these representations, the model calculates probability distributions for candidate tokens that may appear next in the generated text.
Token sampling mechanisms then select tokens sequentially from these probability distributions. Because several candidate tokens may have comparable probability values, different selections may occur during separate generation attempts. As each selected token becomes part of the evolving context, small differences in early token choices may accumulate across subsequent prediction steps.
For this reason, identical prompts may produce different output sequences when processed multiple times. Response variability therefore emerges from the interaction between probability distributions, sampling mechanisms, contextual representations, and sequential token generation within probabilistic AI systems.
Frequently Asked Questions
What does probabilistic output mean in AI systems?
Probabilistic output refers to a generation process in which a model evaluates multiple possible tokens and assigns probability values indicating the likelihood of each token appearing next in a sequence.
Why can the same AI prompt produce different answers?
Different answers may occur because several token sequences may satisfy the probability distributions calculated during inference.
What role do transformer layers play in text generation?
Transformer layers compute contextual relationships between tokens in the input sequence and produce representations used to calculate probability distributions for candidate tokens.
Does response variability indicate an error in an AI model?
Response variability is generally associated with probabilistic token selection mechanisms used during the generation process.
Why do AI tools give different answers to the same question?
AI tools give different answers because modern AI systems generate text using probabilistic token prediction and sampling mechanisms rather than deterministic response selection.
Why does temperature influence AI response variation?
Temperature modifies the sharpness of the probability distribution produced during token prediction. Higher temperature values distribute probability more evenly across tokens, allowing a wider range of possible outputs.
Are identical responses possible from probabilistic models?
Yes. If sampling selects the same sequence of tokens across generation runs, identical responses may occur. However, probabilistic sampling allows multiple possible sequences.
Related Articles
• What Happens Inside an AI Tool After You Click Generate
• Why AI Tools Don’t Learn From Your Prompts
• Why AI Tools Fail Outside Training Conditions
• Core Structural Components of AI Tools
References
- Vaswani, A., et al. (2017). Attention Is All You Need.
https://arxiv.org/abs/1706.03762 - Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003).
A Neural Probabilistic Language Model.
https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf - Radford, A., et al. (2019).
Language Models are Unsupervised Multitask Learners.
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf - Brown, T., et al. (2020).
Language Models are Few-Shot Learners.
https://arxiv.org/abs/2005.14165 - Jurafsky, D., & Martin, J. (2023).
Speech and Language Processing.
https://web.stanford.edu/~jurafsky/slp3/
.