
Introduction
Why AI Generates Incorrect Information refers to the observable behavior of artificial intelligence systems producing outputs that do not align with verified or factual data. This phenomenon is commonly examined within the study of machine learning systems that rely on probability-based modeling and large-scale training datasets.
AI tools are designed to generate responses based on statistical relationships identified during training. Within this framework, incorrect information is observed when generated outputs reflect patterns that are incomplete, inconsistent, or not grounded in validated sources. This characteristic is associated with the structural design of AI systems, where content generation is based on likelihood estimation rather than factual verification.
This behavior is commonly analyzed across multiple dimensions, including data limitations, model architecture, and contextual interpretation processes, all of which contribute to the occurrence of inaccurate or unsupported information in AI-generated outputs.
This document focuses on structural and system-level characteristics of AI output generation. It does not evaluate application-specific implementations or performance variations across individual tools.
Real Examples of AI Giving Incorrect Information
Example 1:
Ask AI: “Who won the FIFA World Cup 2026?”
AI may generate a confident but incorrect answer because it predicts patterns, not real-time facts.
Example 2:
AI may create fake statistics or sources that sound real but do not exist.
Example 3:
AI may give different answers to the same question if asked twice.
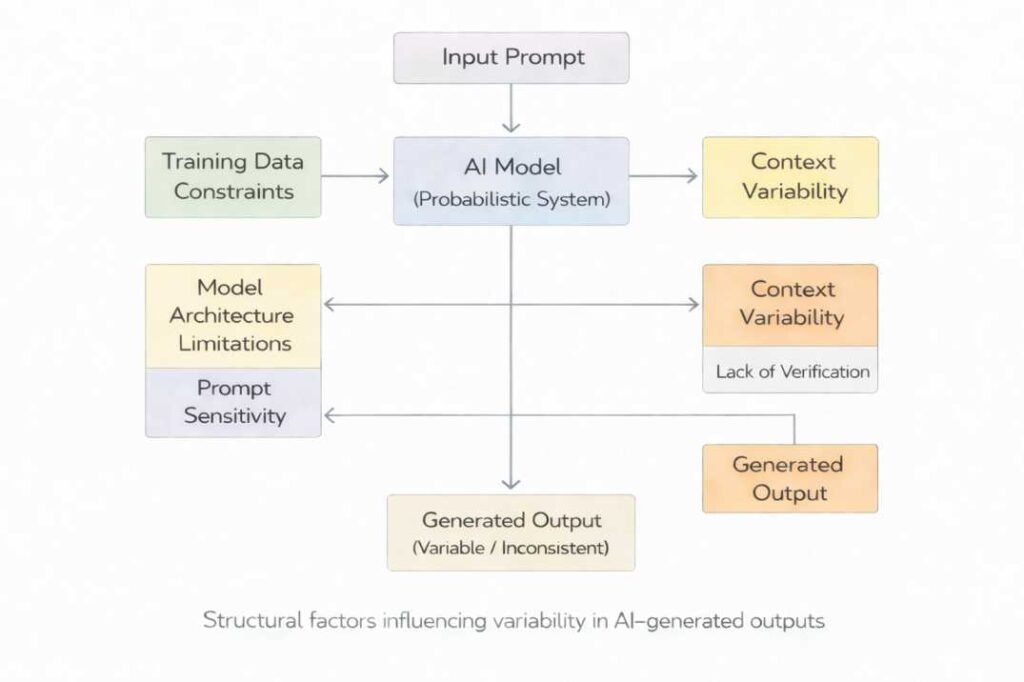
Structural Interaction Model of AI Output Generation
This model establishes that incorrect information is not attributable to a single cause but emerges from the combined effects of multiple structural conditions.
AI-generated outputs are produced through the interaction of multiple structural components operating within a probabilistic framework. These components are not independent; rather, they function as interconnected elements within a unified system.
The generation process is commonly represented as:
• Input prompt (linguistic structure and context signals)
• Probabilistic model processing (token-based sequence prediction)
• Structural constraints (data limitations, architecture boundaries, verification absence)
• Context interpretation mechanisms (ambiguity resolution and framing sensitivity)
These elements collectively influence output formation. Variability or inaccuracy is characterized by interactions between these components that result in patterns not aligned with verifiable information.
Primary Structural Categories of Inaccuracy
These categories provide a framework for organizing the mechanisms through which inaccuracies are observed in AI-generated outputs.
The structural causes of incorrect information in AI systems may be categorized into three primary groups based on their origin within the system:
1. Data-Level Constraints
Factors related to the composition, quality, and scope of training datasets.
2. Model-Level Limitations
Constraints arising from architectural design, token-based processing, and probabilistic generation mechanisms.
3. Interaction-Level Variability
Conditions influenced by input structure, prompt phrasing, and contextual interpretation.
In addition to probabilistic generation mechanisms, data-related constraints further define the boundaries of AI-generated outputs.
Statistical Pattern Dependence
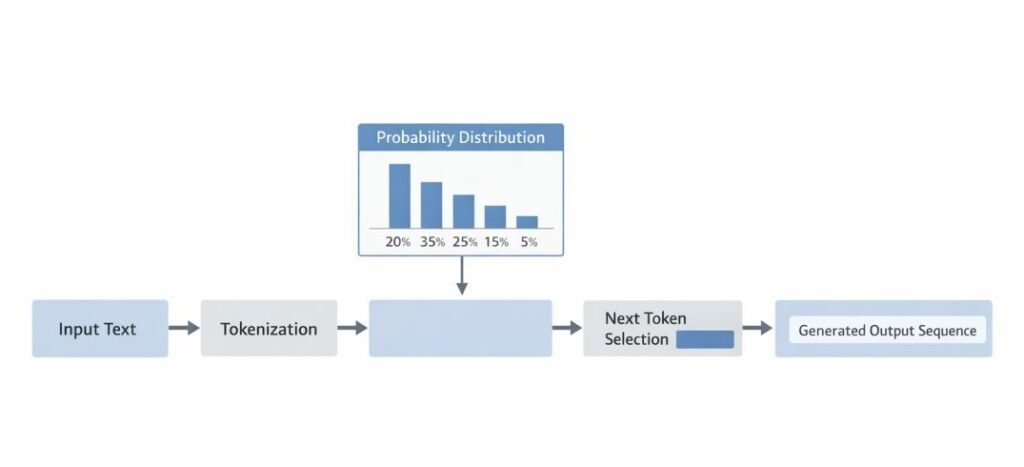
Statistical pattern dependence refers to the mechanism by which AI tools generate outputs based on probabilistic relationships identified within training data. These systems are designed to analyze large volumes of text and model the likelihood of word or token sequences, rather than verify factual correctness.
Within this framework, AI tools are commonly used to predict the most probable continuation of a given input. The generation process is based on learned distributions, where each subsequent element is selected according to patterns identified during training.
This approach is characterized by large language models, where:
- Output generation is driven by probability scores assigned to tokens
- Context is interpreted through sequence modeling rather than factual validation
- Coherence is prioritized based on learned linguistic structures
As a result, responses may reflect patterns that appear logically consistent without being factually accurate. The system does not inherently distinguish between correct and incorrect information, as it operates on likelihood estimation rather than ground truth verification.
Statistical pattern dependence is intended to support language generation tasks, including text completion, summarization, and conversational response formation. Reliance on probability-based modeling is characterized by conditions where generated content includes inaccuracies when learned patterns do not align with verified information.
This behavior occurs across various AI applications where outputs are derived from pattern recognition processes embedded within model training and inference stages.
This mechanism operates in conjunction with training data constraints and model architecture limitations, contributing to the structural conditions under which output variability and inaccuracies are observed.
Training Data Constraints
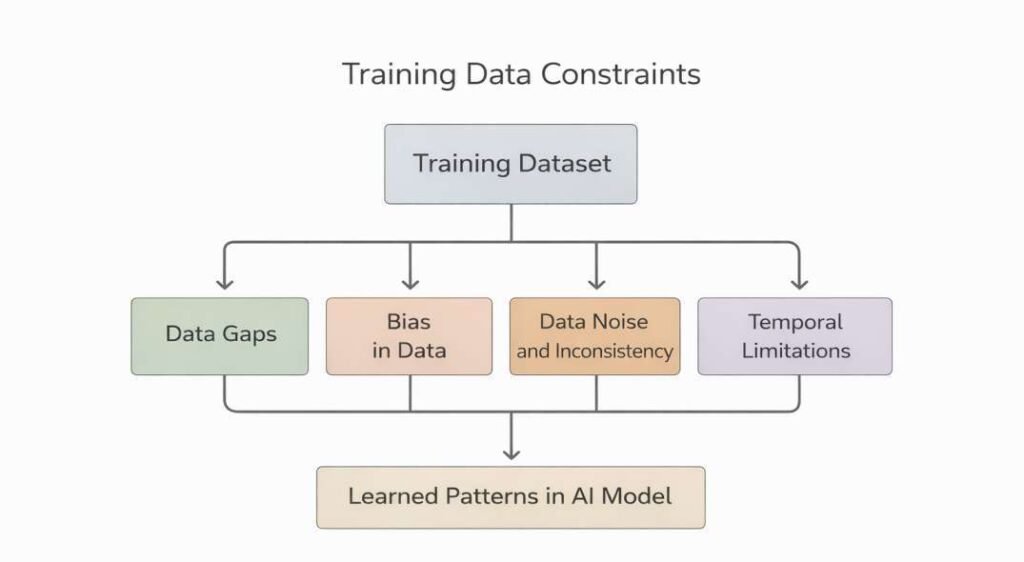
AI tools are designed to learn patterns from large-scale datasets that represent diverse sources of information. The structure, quality, and scope of these datasets define the boundaries within which outputs are generated. Constraints in training data are observed as a primary factor influencing the accuracy and consistency of AI-generated content.
Data Completeness Limitations
Training datasets may not contain comprehensive coverage of all domains, topics, or contexts. Gaps in data representation are observed when certain subjects are underrepresented or absent.
This condition is commonly observed in:
- Niche or specialized knowledge areas
- Emerging topics with limited documented data
- Region-specific or language-specific contexts
As a result, outputs may reflect partial or incomplete information.
Data Quality Variability
Datasets used in AI training are observed to include information of varying reliability and consistency. Differences in source credibility, formatting, and factual correctness are observed within large-scale data collections.
This variability is associated with:
- Mixed authoritative and non-authoritative sources
- Inconsistent data structuring
- Presence of outdated or incorrect records
AI tools are designed to learn from patterns within this data without inherent discrimination between levels of source reliability.
Temporal Limitations
Training data is typically collected and processed up to a specific point in time. AI systems are not continuously updated unless retraining or external integration is performed.
This is characterized by:
- Absence of recent developments
- Lack of real-time updates
- Static knowledge representation over time
Temporal gaps are associated with outputs that do not reflect current information states.
Bias in Data Representation
Bias is characterized by when training datasets disproportionately represent certain perspectives, regions, or demographics over others. These imbalances influence the patterns learned by AI systems.
Common forms include:
- Cultural or linguistic bias
- Overrepresentation of dominant sources
- Underrepresentation of minority viewpoints
Such biases may be reflected in generated outputs as skewed or uneven information.
Data Noise and Inconsistency
Large datasets often contain redundant, conflicting, or unstructured information. Noise within the data is characterized by irregularities that affect pattern learning.
Examples include:
- Duplicate or contradictory entries
- Informal or unverified content
- Inconsistent terminology across sources
AI tools process these inputs statistically, resulting in inconsistent outputs.
Licensing and Accessibility Constraints
Not all data is available for inclusion in training due to legal, ethical, or accessibility restrictions. AI training datasets are therefore limited to accessible and permissible sources.
This constraint is characterized by:
- Proprietary or restricted databases
- Paywalled academic or technical content
- Sensitive or regulated information domains
As a result, certain knowledge areas may not be fully represented in the training process.
Training data constraints are inherent to the design and operation of AI systems. Limitations related to completeness, quality, temporal scope, bias, and accessibility define the informational boundaries of AI-generated outputs. These constraints are commonly observed as contributing factors in the generation of incorrect or incomplete information.
These data-level constraints interact with probabilistic generation processes and architectural limitations, influencing how learned patterns are represented and reflected in generated outputs.
Beyond data-related limitations, the absence of verification mechanisms further influences how outputs are generated.
Lack of Ground Truth Verification
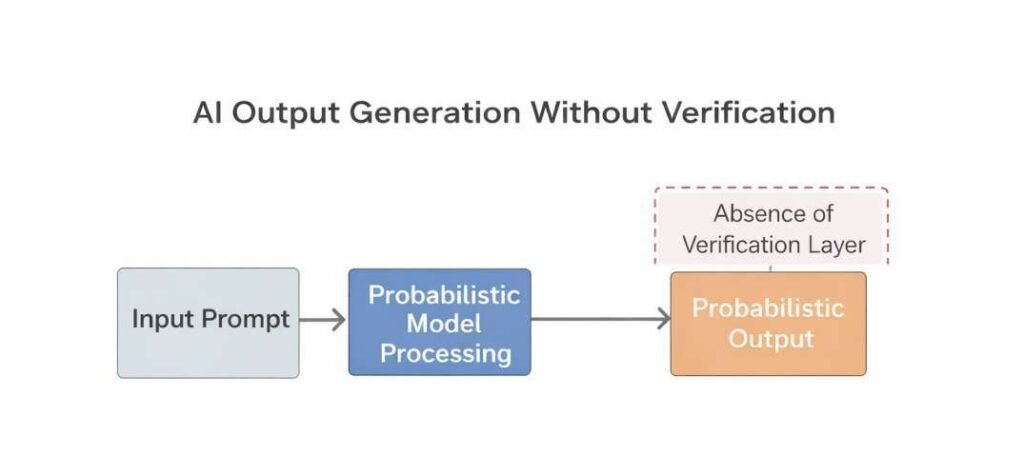
AI tools are designed to generate outputs without inherent mechanisms for validating information against authoritative or real-time sources. The generation process operates independently of external verification unless additional systems are explicitly integrated.
This limitation is commonly observed in environments where outputs are produced without:
- Direct access to verified databases or structured knowledge repositories
- Real-time data retrieval or synchronization mechanisms
- Source attribution or citation validation layers
Within such systems, responses are constructed based on internal representations of training data rather than confirmed factual alignment. As a result, generated content is characterized by the inclusion of statements that are not cross-checked against established references.
The absence of ground truth verification is also observed in scenarios involving:
- Rapidly changing information domains
- Niche or low-representation topics in training data
- Contexts requiring precise factual accuracy
In these cases, the system may produce outputs that are structurally coherent but not aligned with verified or current information. This reflects a separation between language generation processes and external validation frameworks within AI system design.
The absence of verification mechanisms operates alongside probabilistic generation and data constraints, reinforcing conditions in which outputs are produced without alignment to validated information sources.
In addition to structural and data-related constraints, variability is also observed in how input context is interpreted.
Context Interpretation Variability
Context interpretation variability refers to differences in how input meaning is internally represented within AI systems. This variability arises during the processing of contextual signals and is independent of surface-level prompt phrasing.
Input Structure Dependence
AI tools are designed to analyze sequences of tokens, where meaning is inferred from positional and relational patterns. Variations in sentence structure, ordering of information, or inclusion of modifiers may influence how the system interprets the same underlying query.
This is commonly observed in:
- Reordered sentence constructions
- Variations in grammatical framing
- Inclusion or omission of qualifiers
Ambiguity in Language
Natural language often contains ambiguous terms, multiple meanings, or implicit references. AI systems are designed to resolve such ambiguity using statistical likelihood derived from training data.
This is characterized by:
- Selection of unintended meanings
- Misalignment between user intent and generated output
- Context assumptions not explicitly stated in the input
Context Window Limitations
AI tools process input within a defined context window, which represents the maximum amount of text that can be considered at one time. Information outside this window is not incorporated into the response generation process.
This limitation is characterized by:
- Long or multi-part inputs where earlier details are truncated
- Extended interactions where prior context is not retained
- Dense information structures exceeding processing limits
Implicit Context Assumptions
AI systems may infer unstated context based on patterns observed during training. These inferred elements are not explicitly provided but are statistically associated with similar inputs.
This behavior is characterized by when:
- Missing details are supplemented with probable assumptions
- General patterns are applied to specific cases
- Contextual gaps are filled without verification
Multi-Intent Input Handling
Inputs containing multiple intents or mixed objectives are associated with partial or uneven interpretation. AI tools are designed to process input sequentially, which is observed as prioritization of certain segments over others.
This is associated with:
- Incomplete coverage of all input components
- Blending of unrelated topics
- Selective response generation based on dominant patterns
Sensitivity to Prompt Framing
The framing of a prompt, including tone, specificity, and phrasing, influences how the AI system interprets and responds. Even minor linguistic variations may produce different outputs.
This is commonly observed in:
- Direct vs. indirect questioning formats
- Use of domain-specific vs. general language
- Differences in specificity or scope of the query
Context interpretation variability is inherent to AI systems that rely on probabilistic language modeling. It reflects the dependence of output generation on input structure, ambiguity resolution, and contextual constraints within the model’s processing framework.
This variability interacts with prompt structure and probabilistic modeling processes, contributing to differences in how information is interpreted and expressed in generated outputs.
Under certain conditions, the interaction of these structural factors is associated with the generation of unsupported or non-verified content.
Hallucination Phenomenon
The hallucination phenomenon in artificial intelligence refers to the generation of information that is syntactically coherent but not grounded in verifiable data. This behavior is characterized by systems that produce outputs based on probabilistic language modeling rather than factual verification structures.
Definition and Core Characteristics
Hallucination is defined as the production of content that appears plausible in structure and language but lacks correspondence with reliable or existing information sources.
Key characteristics include:
- Formation of statements without supporting data
- Presentation of fabricated details as structured information
- Consistency in language despite factual inaccuracy
This phenomenon is commonly observed in large language models that generate text through statistical associations.
This phenomenon is distinct from contextual variability and prompt sensitivity, as it involves the generation of unsupported content rather than differences in interpretation.
Mechanism of Occurrence
AI tools are designed to predict sequences of tokens based on learned patterns. When gaps exist in training data or contextual input, the system may generate inferred content to maintain linguistic continuity.
This is characterized by when:
- The model encounters incomplete or ambiguous prompts
- Relevant data is absent or weakly represented in training datasets
- The system prioritizes fluency over factual grounding
Types of Hallucinations
Hallucinations may be categorized based on their form and context:
a. Factual Hallucination
Hallucination is observed in conditions where incorrect or non-existent facts are generated, such as inaccurate dates, statistics, or claims.
b. Entity Hallucination
Involves the creation of non-existent entities, including fabricated names of people, organizations, or publications.
c. Citation Hallucination
Refers to the generation of references, sources, or links that do not correspond to actual materials.
d. Contextual Hallucination
Arises when the response deviates from the provided input context, introducing unrelated or assumed information.
Contributing Factors
Several conditions are associated with the occurrence of hallucinations:
- Data Sparsity: Limited or uneven representation of specific topics within training datasets
- Prompt Ambiguity: Inputs lacking clarity or specificity
- Model Generalization: Overextension of learned patterns to unfamiliar contexts
- Lack of internal and external verification structures
These factors are observed to co-occur in conditions where unsupported outputs are generated.
Distinction from Errors
Hallucination is distinct from simple computational or logical errors. While errors may arise from incorrect processing, hallucinations involve the structured generation of content that is not grounded in available data.
This distinction is observed in:
- Coherent but unverifiable narratives
- Structured outputs with fabricated elements
- High linguistic confidence despite lack of evidence
Observational Contexts
The hallucination phenomenon is commonly observed in:
- Open-ended text generation tasks
- Knowledge-based queries without explicit data retrieval
- Creative or inferential prompts
- Situations involving incomplete contextual input
These contexts increase reliance on probabilistic generation processes.
The hallucination phenomenon is an inherent characteristic of AI systems that rely on probabilistic language generation. It is observed when outputs are produced without grounding in verifiable data, influenced by training limitations, contextual ambiguity, and the absence of verification structures.
This phenomenon emerges through the interaction of data limitations, probabilistic generation mechanisms, and the absence of verification structures within the system.
These observed behaviors are further shaped by inherent limitations within the underlying model architecture.
Model Architecture Limitations
AI tools are designed using predefined computational architectures that determine how data is processed, represented, and generated. These architectures establish structural boundaries that influence the accuracy, consistency, and interpretability of outputs. Within these systems, several limitations are observed due to the design and operational mechanisms of the models.
Token-Based Processing Structure
AI models are designed to process text as sequences of tokens rather than complete semantic units. Each token represents a fragment of language, and outputs are generated by predicting the next token in a sequence.
This structure is commonly used within transformer-based architectures, where:
- Language is decomposed into smaller units
- Relationships are modeled through token probabilities
- Meaning is inferred indirectly through sequence patterns
This approach is observed as outputs that are structurally coherent but not semantically accurate.
Fixed Parameter Representation
AI models operate using a fixed set of parameters that are established during the training phase. These parameters encode learned patterns but do not dynamically update during standard inference.
This limitation is observed in:
- Static knowledge representation after training completion
- Inability to incorporate new information without retraining
- Dependence on historical data distributions
As a result, outputs may reflect outdated or incomplete knowledge states.
Absence of True Semantic Understanding
AI tools are designed to simulate language understanding through statistical associations rather than possessing intrinsic comprehension.
This is observed in:
- Pattern matching instead of conceptual reasoning
- Lack of awareness of meaning beyond learned correlations
- Inability to distinguish between factual accuracy and plausible structure
The system generates responses based on learned relationships rather than verified understanding.
Context Window Constraints
AI models operate within a limited context window, which defines how much input information can be processed at a given time.
This constraint is observed as:
- Loss of earlier context in longer interactions
- Incomplete interpretation of extended inputs
- Fragmented response generation when input exceeds limits
The context window size directly influences how much information the model can retain during processing.
Probabilistic Output Generation
AI tools are designed to produce outputs based on probability distributions over possible token sequences. The selection of outputs is influenced by likelihood rather than deterministic correctness.
This mechanism is observed in:
- Multiple valid outputs for the same input
- Variability in responses across repeated queries
- Lack of guaranteed factual consistency
Lack of Built-In Verification Layers
Model architectures do not inherently include mechanisms for validating generated information against external or internal sources.
This is observed in systems that:
- Generate outputs without fact-checking components
- Do not reference authoritative databases during inference
- Operate independently of validation frameworks
- Produce outputs without embedded verification processes
This reflects the separation between generation mechanisms and validation systems within AI model design.
Generalization Boundaries
AI models are designed to generalize from training data, but this generalization is constrained by the diversity and structure of that data.
This is associated with:
- Reduced accuracy in niche or underrepresented domains
- Overextension of learned patterns to unrelated contexts
- Inconsistent handling of edge cases
Generalization is limited to patterns encountered during training.
Model architecture limitations are inherent to the design of AI systems. These limitations are observed in token-based processing, fixed parameter structures, probabilistic generation, and the absence of verification structures. Such constraints define how AI tools process and generate information within their operational boundaries.
These architectural constraints operate in combination with data-level limitations and probabilistic modeling processes, shaping the structural boundaries of output generation.
In addition to internal processing mechanisms, variations in input construction also influence output generation.
Prompt Sensitivity
Prompt sensitivity refers specifically to variations in output resulting from changes in input phrasing, structure, or linguistic framing. This condition is distinct from internal context interpretation and is directly associated with observable differences in prompt construction.
Input Structure Dependence
AI tools are designed to process prompts as sequences of tokens. The arrangement, order, and emphasis within these tokens contribute to how the system interprets the request.
This is observed in cases where:
- Reordered sentence structures produce different outputs
- Additional qualifiers alter the scope of interpretation
- Omitted details lead to generalized responses
Linguistic Variability
Natural language contains multiple ways to express similar intent. AI systems are designed to map these variations to learned patterns, but consistency is not guaranteed across all phrasing forms.
Variability is observed in:
- Synonyms or alternate wording
- Formal versus informal language structures
- Regional or domain-specific terminology
Ambiguity in Input
Prompts that contain ambiguous or undefined elements may be interpreted in multiple ways. AI tools are designed to resolve ambiguity using probabilistic inference rather than deterministic clarification.
This condition is observed when:
- Terms have multiple meanings
- Context is incomplete or unspecified
- The scope of the query is not clearly defined
Context Length and Detail
The level of detail within a prompt influences how the AI system constructs its response. Short or minimal prompts are observed as broader outputs, while longer prompts introduce additional contextual signals.
This is observed in:
- Under-specified inputs leading to generalized content
- Overloaded inputs affecting focus or coherence
- Inclusion of irrelevant context altering interpretation
Sequential Dependency
AI tools process prompts in a sequential manner, where earlier tokens influence the interpretation of subsequent tokens. The position of information within a prompt can affect output generation.
This is commonly observed when:
- Key instructions appear at different positions
- Late-stage qualifiers modify earlier context
- Multi-part prompts introduce shifting priorities
Sensitivity to Instruction Framing
The framing of instructions within a prompt influences how the system prioritizes content generation. AI tools are designed to respond differently based on directive language patterns.
This includes:
- Declarative versus interrogative formats
- Explicit constraints versus open-ended phrasing
- Single-task versus multi-task prompts
Domain Context Influence
Prompts that include domain-specific language activate different learned patterns within the model. Variations in domain cues are associated with distinct interpretations.
This is observed in:
- Technical versus general language usage
- Inclusion of specialized terminology
- Cross-domain ambiguity within the same prompt
Prompt sensitivity is a structural characteristic of AI systems, arising from their reliance on probabilistic language modeling. Variations in input phrasing, structure, and context are observed to influence output generation, reflecting the system’s dependence on token-based interpretation rather than fixed semantic understanding.
This condition interacts with context interpretation mechanisms and probabilistic generation processes, contributing to variability in output formation across similar inputs.
When considered collectively, these structural factors form an interconnected system influencing output generation.
Integrated Structural Dependency
This dependency structure reflects a layered system in which inaccuracies emerge from cumulative interactions rather than singular points of failure.
The structural causes described are not isolated mechanisms but interdependent components within AI system design. Data constraints influence learned representations, which are processed through architectural limitations and interpreted through context-dependent mechanisms. The absence of verification layers further separates generated outputs from validated information sources.
Conclusion
AI tools are designed to generate outputs through probability-based modeling, where responses are formed based on learned patterns rather than verified knowledge systems.
Incorrect information is observed as a result of structural characteristics including:
- Statistical pattern dependence
- Training data constraints
- Lack of verification structures
- Context interpretation variability
- Hallucination phenomena
- Model architecture limitations
- Prompt sensitivity
These elements define the structural conditions under which AI systems generate outputs within their operational framework.
FAQs
Why do AI tools generate incorrect information?
AI tools are designed to generate outputs based on learned distributions in training data. Incorrect information is observed when generated patterns do not align with established or verifiable data.
What is meant by hallucination in AI systems?
Hallucination refers to the generation of content that appears coherent but is not supported by verifiable data. This phenomenon is observed when the system produces inferred or fabricated details.
Does training data affect the accuracy of AI outputs?
Training data defines the statistical patterns from which AI systems generate outputs. Limitations such as incompleteness, inconsistency, or temporal constraints are observed as influencing the structure and content of generated responses.
Do AI tools verify information before generating responses?
AI tools are not inherently designed to perform real-time verification. Outputs are generated without automatic cross-checking against external or authoritative sources unless additional systems are integrated.
Can input phrasing influence incorrect outputs?
Input phrasing is observed to influence how AI systems interpret context. Variations in structure, specificity, or ambiguity are associated with differences in generated outputs.
Do AI systems understand the information they generate?
AI tools operate through pattern recognition and token prediction. They do not possess semantic understanding or awareness of correctness in the information they produce.
References
- OpenAI. GPT-4 Technical Report. Available at: https://arxiv.org/abs/2303.08774
- Google Research; Timnit Gebru et al. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Available at: https://dl.acm.org/doi/10.1145/3442188.3445922 This behavior is examined in research on probabilistic language models and large-scale training systems as described in referenced technical literature.
- Stanford University (CRFM). On the Opportunities and Risks of Foundation Models. Available at: https://arxiv.org/abs/2108.07258
- MIT. Artificial Intelligence Research Resources. Available at: https://ai.mit.edu
- DeepMind. On the Capabilities and Limitations of Large Language Models. Available at: https://arxiv.org/abs/2201.11903
- National Institute of Standards and Technology. AI Risk Management Framework (AI RMF 1.0). Available at: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
- European Commission. Ethics Guidelines for Trustworthy AI. Available at: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai
- Top 10 Free AI Tools for Beginners (2026 Guide) - April 3, 2026
- How to Use ChatGPT for Beginners (Step-by-Step Guide) - March 31, 2026
- Why AI Tools Fail Outside Training Conditions - March 29, 2026