
Introduction
The assumption that AI tools learn from prompts is common in public discussions of artificial intelligence systems. When users observe contextually responsive outputs, it may appear that the system is incorporating new information into its knowledge structure.
In most deployed AI systems, however, user interaction occurs during inference, not training. Inference applies stored parameter configurations to runtime inputs without modifying those parameters.
Understanding why AI tools do not learn from prompts requires distinguishing between two computational stages:
- Training, during which parameter weights are adjusted using structured datasets.
- Inference, during which stored parameters are applied to new inputs without revision.
This structural separation defines how AI systems operate in deployed environments.
The Two-Phase Structure of AI Systems
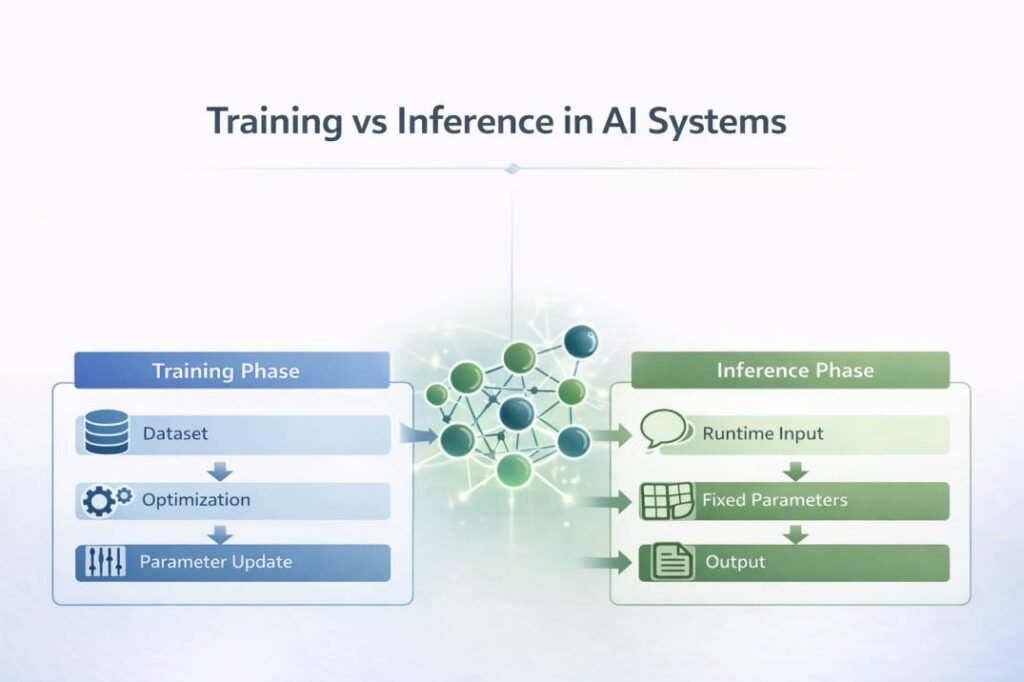
AI systems operate through two distinct computational stages: training and inference. These stages differ in objective, environment, and parameter behavior.
Training involves parameter formation. Inference involves parameter application.
1. Training Phase: Parameter Formation
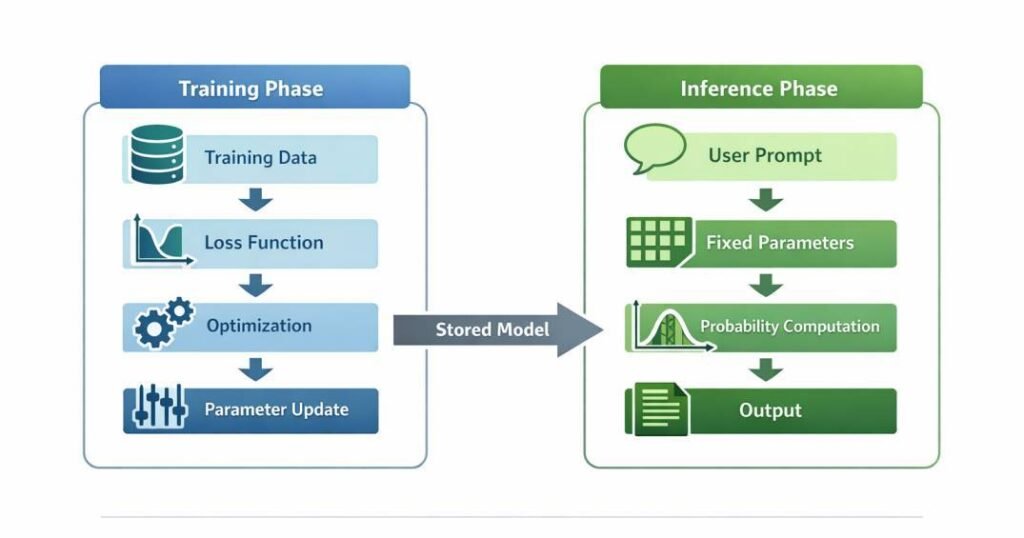
The training phase encodes statistical relationships into numerical parameter weights. During this stage:
- Large-scale datasets are processed iteratively.
- A loss function quantifies prediction error.
- Optimization algorithms adjust parameter weights.
- Representational patterns are refined across multiple passes.
The objective of training is to approximate a mapping function that relates input patterns to output distributions. Parameter updates continue until convergence criteria are satisfied under defined computational constraints.
Training modifies internal weight matrices, bias terms, and representational embeddings, altering how future inputs are evaluated. This separation between parameter optimization and runtime application is widely described in foundational deep learning literature (Goodfellow, Bengio & Courville, 2016; Bishop, 2006).
Training occurs within controlled development environments prior to deployment. Once complete, the resulting parameter configuration is stored for operational use.
2. Inference Phase: Parameter Application
Inference is the operational phase in which stored parameters are applied to new input data. During inference:
- The stored parameter configuration is applied without gradient-based modification.
- Input data is transformed into internal representations.
- Weighted transformations propagate through the model architecture.
- Probability distributions or score values are computed.
Inference is computationally active but structurally non-adaptive. It applies encoded statistical mappings without revising them.
Structural Comparison: Training and Inference Phases in AI Systems
| Feature | Training | Inference |
|---|---|---|
| Objective | Parameter optimization | Parameter application |
| Data Type | Structured training dataset | Runtime input prompt |
| Parameter State | Updated iteratively | Operationally applied |
| Compute Profile | Gradient-based, high resource | Forward-pass, latency constrained |
| Environment | Development pipeline | Deployed runtime system |
Training Data vs Runtime Input Data
The misconception that AI tools learn from prompts often arises from misunderstanding the difference between training data and runtime input data.
Training Data
Training data is used to construct the internal parameter structure of the model. It determines:
- Representational boundaries
- Feature sensitivities
- Decision surfaces
- Probability calibration
During training, input-output examples guide parameter adjustments through gradient-based optimization or other statistical procedures. Each training example contributes to incremental parameter updates.
Training data directly influences how the model behaves in future inference events.
Runtime Input Data (Prompts)
Runtime input data includes user-submitted prompts processed after deployment. This data:
- Is transformed into internal embeddings.
- Is evaluated using stored weights.
- Influences output distributions during that interaction.
- Does not trigger parameter updates.
The system computes outputs by applying pre-existing statistical relationships to the prompt representation.
Runtime input affects output generation only through activation of encoded patterns, not through structural learning.
Representation Space and Activation
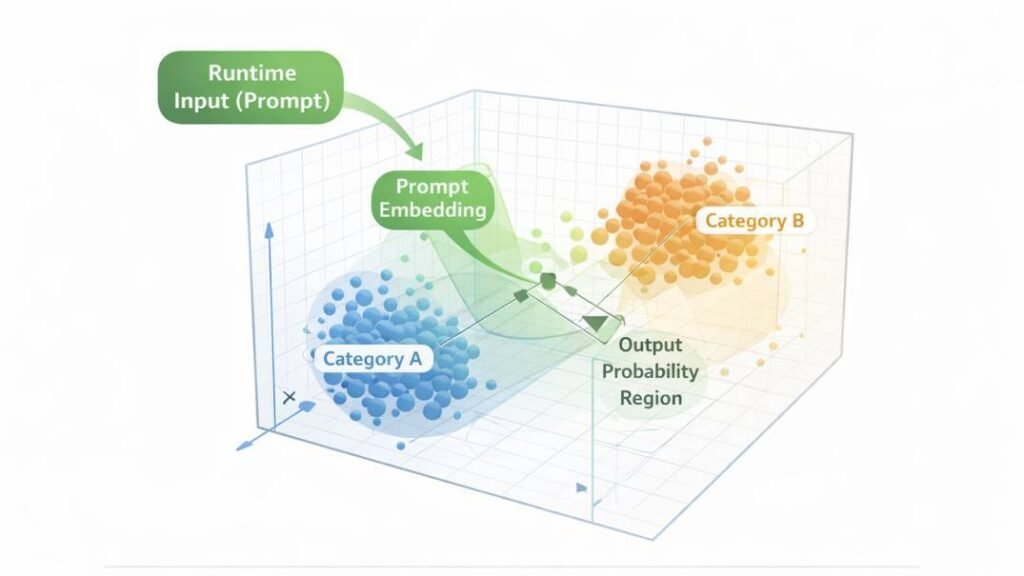
Prompts are converted into numerical vector embeddings that determine their position within this fixed high-dimensional representational space.
This space is defined by:
- Parameterized embedding matrices
- Learned feature transformations
- Layered nonlinear activations
When a prompt is submitted:
- Tokens are mapped into vector embeddings.
- Embeddings are positioned within the representational space.
- Stored parameter weights determine how the representation propagates through layers.
- Output probabilities emerge from the final activation states.
The representational space itself was shaped during training. Inference operates within that fixed geometric structure.
The diagram above illustrates how prompt embeddings occupy specific regions within a fixed geometric space structured during training. Clustered regions correspond to statistically dense pattern areas, while output probability regions reflect learned decision surfaces encoded in parameter weights. During inference, prompts are positioned within this predefined space rather than altering its structural boundaries.
The prompt influences positional activation within this space but does not modify its geometric structure.
Why Adaptive Behavior Appears
Several runtime mechanisms contribute to the perception that AI tools learn from prompts.
Contextual Conditioning
Many AI systems maintain session-level context windows. Previous exchanges may be included in subsequent input representations. This produces continuity across turns.
Context inclusion is a form of input expansion. It does not involve parameter modification.
Probabilistic Sampling
Generative systems compute probability distributions over possible next tokens or outputs. Sampling from these distributions can introduce variation across responses.
This variability reflects distributional computation rather than incremental learning.
Version Updates and Retraining
AI systems may be periodically retrained or fine-tuned by developers. These updates occur offline through structured training cycles and result in new parameter configurations.
Observed changes in behavior over time often reflect model redeployment rather than prompt-based adaptation.
Parameter modification requires controlled retraining procedures using curated datasets and computational optimization processes external to user interaction.
Common Misconception
Misconception:
“If the system responds differently after I clarify something, it must be learning.”
Clarification:
Behavioral variation across turns reflects expanded input context within the session window, not modification of stored parameter weights.
Computational Sequence After Prompt Submission
When a user submits a prompt, a defined computational workflow begins.
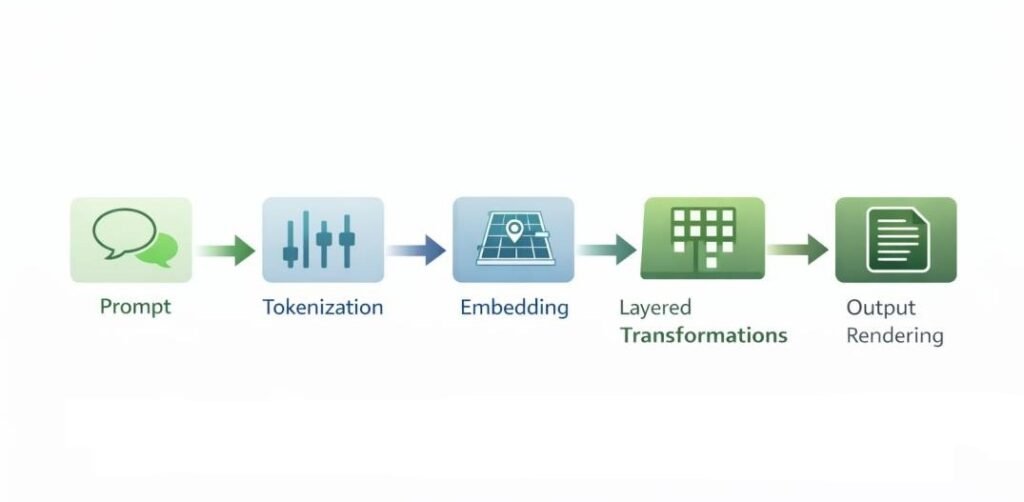
1. Input Acquisition
The system receives the prompt via an interface layer. The text is temporarily stored within the session environment.
2. Preprocessing and Normalization
The input undergoes formatting procedures:
- Tokenization
- Normalization
- Structural validation
This ensures compatibility with model expectations.
3. Embedding Generation
Tokens are converted into numerical embeddings. Each token corresponds to a vector representation derived from trained embedding matrices.
These vectors position the input within the model’s representational framework.
4. Layered Transformation
The embedded representation propagates through internal layers defined by the layered architecture of AI tools, where stored parameter weights govern transformation sequences. In neural architectures, this involves:
- Weighted matrix multiplications
- Nonlinear activation functions
- Residual connections (in some architectures)
- Attention mechanisms (in transformer-based systems)
Each layer transforms the representation according to stored weights.
5. Output Distribution Computation
The final layer computes a probability distribution over possible outputs. In generative systems, this may occur sequentially across token positions.
Probability values reflect statistical relationships learned during training.
Probability Distribution Mechanics During Inference
During inference, the final layer of many AI systems computes a vector of unnormalized score values, often referred to as logits. These values are transformed into a normalized probability distribution through a function such as softmax, which ensures that the total probability mass equals one.
The resulting distribution represents the model’s relative confidence across potential outputs. In classification systems, the highest-probability category may be selected deterministically. In generative systems, output tokens may be selected through deterministic decoding (e.g., greedy selection) or stochastic sampling strategies.
Sampling parameters, such as temperature scaling or top-k and nucleus selection thresholds, influence how probability mass is redistributed prior to token selection. These mechanisms affect output variability without altering stored parameter weights.
Thus, output variation arises from distributional evaluation and decoding configuration rather than structural learning during inference.
6. Output Rendering
The system converts numerical output states into human-readable text or structured data. This rendering stage does not involve additional learning.
Distinguishing Activation from Learning
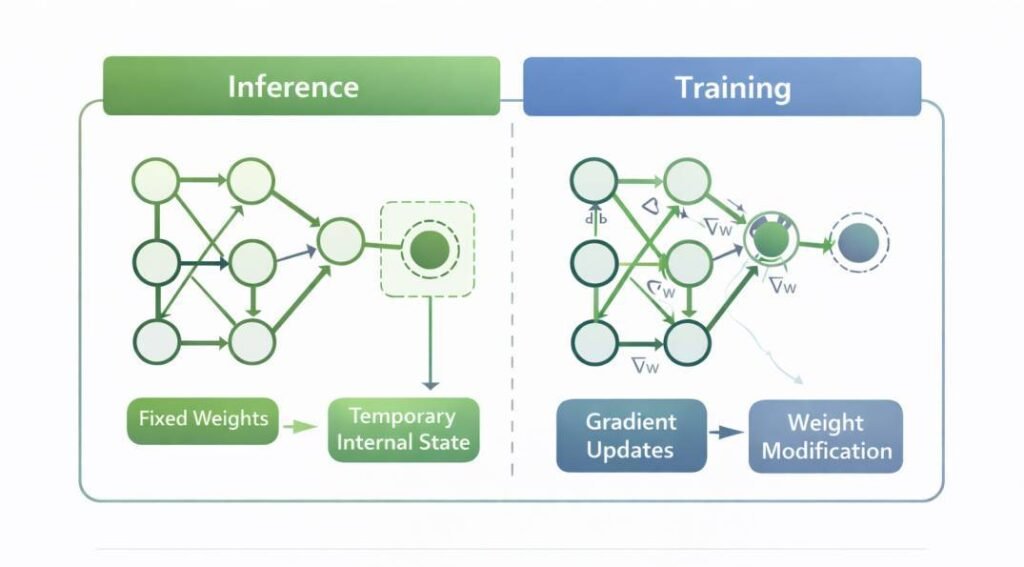
Activation refers to the process by which stored weights respond to input data. Learning refers to the modification of those weights.
During inference:
- Stored weights are operationally applied.
- Gradient-based modification is not initiated.
Activation changes internal representational states temporarily during computation. Learning changes the parameter configuration permanently through optimization.
User prompts trigger activation.
Training triggers learning.
Stability and Deployment Boundaries
The separation between training and inference supports operational stability. This staged separation reflects fundamental differences between AI tools and traditional software systems, particularly in how statistical parameters replace rule-based execution logic.
Continuous runtime parameter modification would alter calibration behavior, system stability characteristics, and traceability properties within deployed environments.
By maintaining fixed parameters during inference, AI tools operate within bounded computational limits.
Learning is restricted to controlled development cycles to preserve reliability and traceability. Governance frameworks such as the NIST AI Risk Management Framework emphasize controlled modification procedures to preserve traceability in deployed AI systems.
Computational Constraints During Runtime Inference
Inference is executed within defined computational resource boundaries. Unlike training, which may involve distributed gradient computation across large-scale hardware clusters, inference typically operates under latency, memory, and throughput constraints associated with deployed environments.
During runtime:
- Parameter weights are loaded into memory.
- Matrix multiplications are executed using hardware accelerators or optimized compute libraries.
- Output generation may proceed token-by-token in autoregressive systems.
- Latency constraints may limit context window size or decoding depth.
These constraints influence response time and resource utilization but do not alter parameter values.
Inference performance characteristics—such as processing speed, memory footprint, and throughput—reflect implementation architecture rather than adaptive learning behavior. The system continues to apply stored statistical mappings regardless of computational load conditions.
Operational constraints shape how efficiently inference executes, not how the model learns. Structural modification occurs only within controlled retraining pipelines external to deployed runtime systems.
Representational Limits
Inference operates within representational boundaries established during training. These boundaries include:
- Vocabulary scope
- Feature encoding capacity
- Pattern recognition limits
- Distributional assumptions
Prompts cannot introduce new structural categories into the model. They can only activate relationships already encoded.
This constraint explains why AI systems may generalize within learned patterns but cannot autonomously expand conceptual scope without retraining.
Distribution Alignment and Output Stability
Inference behavior is influenced by the relationship between runtime input distribution and the statistical distribution observed during training. AI systems are calibrated based on patterns encoded from training datasets. When runtime inputs fall within similar distributional boundaries, output probabilities tend to remain stable relative to learned statistical structure.
If runtime input diverges from the statistical structure encountered during training, internal activations may map to regions of representational space with lower density support. In such cases, output probabilities may become less calibrated relative to real-world correctness, without any alteration to the stored parameter configuration.
This phenomenon does not indicate learning failure during inference. Rather, it reflects distributional misalignment between training data and operational input conditions.
Output variability under distributional shift arises from fixed parameter application across unfamiliar representational regions. The model continues to compute probability distributions according to encoded statistical relationships, but calibration may vary when encountering patterns that were underrepresented during training.
Research in machine learning has examined this relationship extensively within studies of calibration and generalization under dataset shift. Empirical analyses demonstrate that predictive confidence may degrade when input distributions diverge from training conditions, even though parameter weights remain unchanged (Guo et al., 2017; Ovadia et al., 2019). These findings reinforce the distinction between fixed-parameter inference behavior and structural learning.
Inference therefore operates within distributional boundaries established during model development. Variability under distributional shift reflects evaluation across unfamiliar statistical regions rather than runtime parameter modification.
Extended Operational Scenario
Consider a prompt requesting analysis of a financial report.
The system:
- Tokenizes the report text.
- Maps tokens into vector embeddings.
- Positions the embeddings within representational space.
- Applies stored parameter weights through layered transformations.
- Computes probability distributions over potential summary structures.
- Generates output text via sequential sampling.
- Renders the response.
If a follow-up question is asked within the same session, prior content may be included in the input window. The second response reflects expanded input context, not parameter modification.
Once the session concludes, internal weights remain identical to their pre-interaction state.
Retraining as a Separate Computational Event
Parameter modification requires:
- Structured datasets
- Defined optimization objectives
- Iterative gradient computation
- Validation under controlled conditions
Retraining occurs outside runtime inference environments. It produces new parameter configurations that replace previous versions upon redeployment.
Learning is therefore episodic and development-controlled, not continuous during user interaction.
Conclusion
AI tools do not learn from individual prompts because runtime interaction occurs during inference, where stored parameter weights are applied without adjustment. Training data shapes these parameters prior to deployment through structured optimization procedures. Prompts activate previously encoded statistical mappings without initiating structural parameter revision.
The perception of learning arises from contextual conditioning, probabilistic sampling behavior, and periodic model redeployment cycles. These mechanisms create adaptive-seeming responses without modifying internal parameter structures.
The distinction between activation and learning clarifies the operational boundaries of AI systems. Prompts influence outputs through activation within fixed representational space rather than through parameter revision.
This separation defines how AI tools function within deployed computational architectures.
References
Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016.
https://www.deeplearningbook.org/
Vapnik, Vladimir N. Statistical Learning Theory. Wiley, 1998.
Bishop, Christopher M. Pattern Recognition and Machine Learning. Springer, 2006.
Murphy, Kevin P. Machine Learning: A Probabilistic Perspective. MIT Press, 2012.
Guo, Chuan, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger.
“On Calibration of Modern Neural Networks.” Proceedings of the 34th International Conference on Machine Learning (ICML), 2017.
https://proceedings.mlr.press/v70/guo17a.html
Ovadia, Yaniv, Emily Fertig, Jie Ren, et al.
“Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift.” Advances in Neural Information Processing Systems (NeurIPS), 2019.
National Institute of Standards and Technology (NIST). Artificial Intelligence Risk Management Framework (AI RMF 1.0). 2023.
https://www.nist.gov/itl/ai-risk-management-framework