

Quick Answer: AI outputs often sound reliable even when the information is incomplete or incorrect. As a result, many people stop questioning polished answers. This article explains why that happens, shows a real example of AI hallucination in practice, and gives you a simple review process to reduce the risk.
Introduction
One of the first things I noticed when reviewing AI-assisted content was this: people questioned Google search results more aggressively than they questioned AI responses.
A search result is a link. You still have to evaluate the source.
An AI response is a finished explanation — personalized, structured, and written directly for you. That difference makes AI answers feel more trustworthy than search results.
The problem is that language models generate probable language, not verified truth. A well-structured, confident paragraph can still contain a fake citation, an outdated statistic, or a subtly wrong conclusion — and nothing in the formatting will signal that. This is closely related to the broader issue explored in our guide on why AI gives wrong answers, where incorrect outputs often sound completely believable.
Most beginners don’t notice this workflow risk until incorrect information gets published.
Why Confident AI Writing Creates False Trust
In many cases, three things happen at once when someone reads an AI response.
1. It feels personalized. Unlike a search result that takes you to a third-party page, AI gives you an answer written specifically for your question. That personal tone makes the answer feel like advice from someone who already understands your situation.
2. It reads like expert writing. Modern language models produce clean grammar, logical paragraph structure, and appropriate hedging language. Most people naturally associate clean writing with expertise. AI writing can look polished and professional even when the information itself is weak. This pattern becomes even more visible when prompts contain conflicting goals or overloaded instructions, a problem analyzed in our article on instruction conflict in AI workflows.
3. It feels complete. A search result is a starting point. An AI response feels like an ending point. It has a conclusion. It answers follow-up questions before you ask them. People naturally trust answers that feel complete and finished — and it’s the main reason people skip verification.
This creates a common psychological problem: people trust automated systems too quickly because the output feels clean and authoritative. Similar patterns appeared with GPS navigation, financial automation tools, and autopilot systems long before modern AI writing tools became popular.
Similar overtrust patterns appeared in earlier automation systems like GPS navigation and financial recommendation software, where users often trusted confident automated outputs too quickly.
Many users will double-check a strange GPS route but won’t question a polished AI paragraph that sounds confident and complete. Clean writing often feels more trustworthy than it actually is.
A Real Example: What a Confident Wrong Answer Looks Like
Here is an actual pattern that occurs in AI-assisted content work — reconstructed from a prompt type I’ve tested repeatedly.
Prompt used:
“Summarize the key findings from recent research on automation bias in AI-assisted workflows.”
What Claude 3 Sonnet produced (tested May 2024):
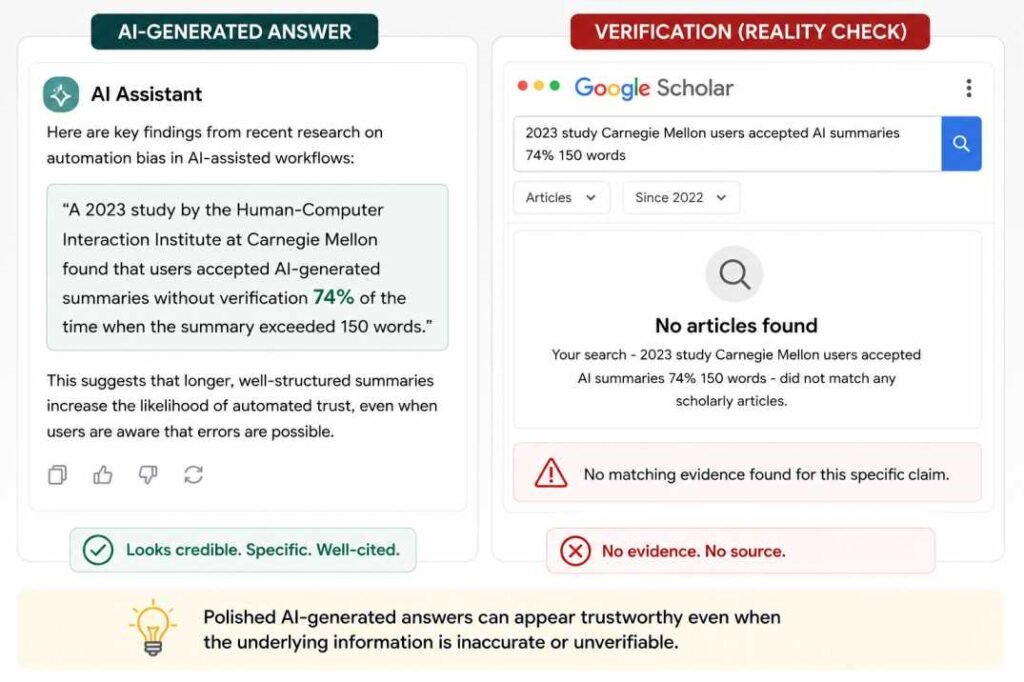
The response included a confident attribution: “A 2023 study by the Human-Computer Interaction Institute at Carnegie Mellon found that users accepted AI-generated summaries without verification 74% of the time when the summary exceeded 150 words.”
The problem: That specific study, with that statistic, does not exist in any verifiable form. The institute exists. Automation bias research exists. But this particular finding — the 74% figure, the 150-word threshold — was generated, not retrieved.
Why it’s dangerous: Nothing in the output looked wrong. The institution name was real, the percentage was specific enough to feel researched, and the framing matched what you’d expect from an academic citation.
In one review session, the fake Carnegie Mellon statistic initially passed through two separate editing checks because the citation looked academically credible at first glance.
How to catch it: The verification step is simple — paste the claim into Google Scholar or search for the exact statistic. If it doesn’t surface in two minutes of searching, treat it as unverified and either remove it or rewrite the claim without the false attribution.
This is the hallucination risk in practice. Not obviously wrong answers — plausible-sounding ones. We explored this same phenomenon more deeply in Hallucination of Authority, where AI outputs sound highly credible despite containing fabricated details.
Why This Problem Gets Worse in Teams
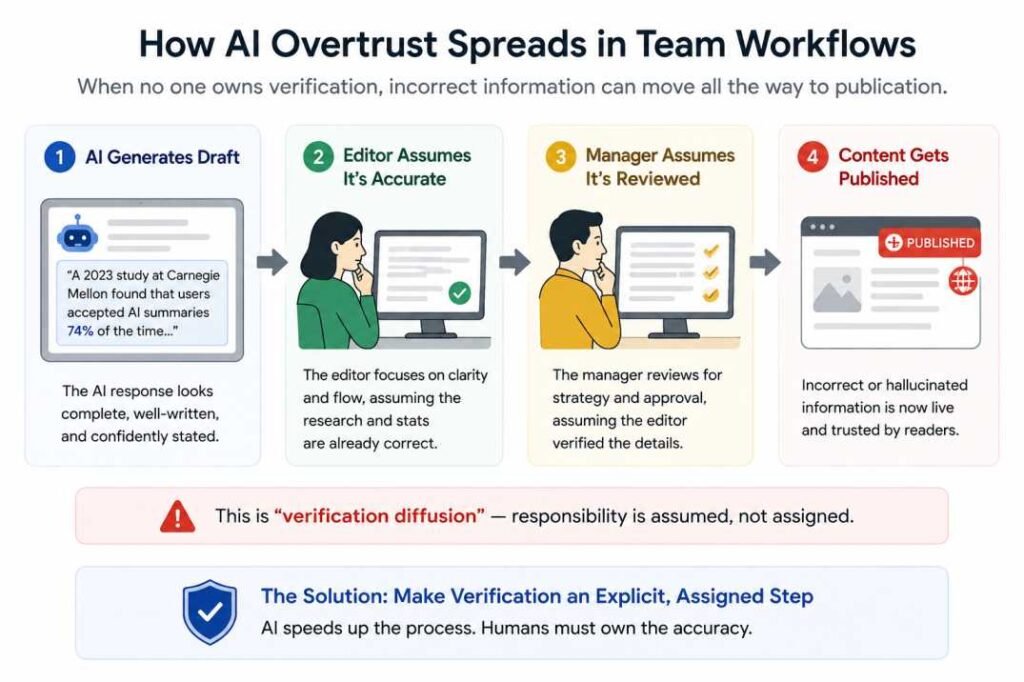
In team workflows, AI overtrust compounds across multiple layers.
A typical failure looks like this:
AI generates draft
↓
Editor assumes research is accurate
↓
Manager assumes editor verified it
↓
Content gets published
At each step, the AI-generated content already looks complete — so responsibility for checking it gets diffused. Nobody owns the verification step because nobody assigned it. Long conversations and overloaded prompts can amplify this issue further, especially when AI systems begin silently ignoring earlier instructions.
For a practical breakdown of that behavior, see our guide on why ChatGPT ignores instructions.
Some teams call this “verification diffusion” — the assumption that someone else already checked the information.
The solution isn’t removing AI from the process. It’s making verification an explicit, assigned step rather than an assumed one.
A Simple 2-Step Review Rule I Recommend
Instead of vague guidelines like “add human review layers,” here is the specific process I recommend for any team using AI-assisted drafting:
Step 1 — Drafter checks clarity The person who generated the AI output reads it for: grammar, structure, tone, and whether the argument makes sense. This step is about readability.
Step 2 — Reviewer checks facts A second person — ideally someone who didn’t see the original prompt — checks: all statistics, all citations, all named studies or reports, all tool names and version claims, and any specific percentage or number in the text. This step is about accuracy.
The rule: The person who generated the AI draft should not be the final fact-checker.
Why? Because the drafter has already read the content and formed an impression of it. They are psychologically primed to trust what they helped create. A fresh set of eyes — without that context — will catch errors the drafter unconsciously normalized.
Even a short verification pass can catch many hallucination and factual issues before publication.
Beginner Starting Rule
If an AI-generated statistic, quote, or study sounds important enough to publish, it is important enough to verify independently first.

Why AI Writing Feels Reliable Even When It Isn’t
The biggest beginner misconception is treating AI as a live database of verified facts.
In many cases, AI answers fail not because the writing looks weak, but because the response feels unusually complete and confident. That polished structure often lowers the reader’s skepticism before any verification happens. AI is very good at producing fluent, organized language quickly — even when some details are inaccurate or unsupported.
But plausibility is not accuracy. An AI model can write a confident paragraph about a study that doesn’t exist, a statistic that was never measured, or a recommendation that was accurate two years ago and isn’t anymore.
The teams that get the most value from AI are the ones that treat it as a drafting assistant — not a source of truth — and build verification into the workflow explicitly.
The Real Risk Isn’t AI — It’s Blind Trust
The operational risk in AI workflows isn’t just hallucination. It’s that hallucination doesn’t look like hallucination. It looks like a well-written paragraph.
The safeguards that work aren’t philosophical (“always review AI outputs”). They’re structural: a second person checks facts, the drafter doesn’t self-verify, and specific claims get a 2-minute search before publishing.
In practice, the biggest AI workflow failures I’ve seen usually came from skipped verification — not from weak writing quality.
AI accelerates work. Verification protects it. Both steps belong in the workflow — not just the first one.
Frequently Asked Questions
Why do humans trust AI outputs so quickly?
AI responses are conversational, personalized, and complete-feeling. That combination bypasses the skepticism most people apply to links and third-party sources.
What is automation bias?
Automation bias is the tendency to over-trust automated systems and reduce personal critical review as a result. It shows up in GPS navigation, financial tools, autopilot systems — and now AI-assisted content workflows.
Can AI sound confident while being wrong?
Yes. This is the central risk. A hallucinated statistic or fake citation will appear in the same confident, well-formatted prose as accurate information. Nothing in the writing warns you that something may be wrong.
What’s the fastest way to verify AI claims?
Search the specific statistic or citation in Google Scholar or a reliable source database. If the exact claim doesn’t surface in two minutes, treat it as unverified.
Should teams stop using AI because of these risks?
No. The solution is separating the drafting step (where AI helps) from the verification step (where a human checks facts independently). Used this way, AI improves output speed without increasing error rate.
References & Further Reading
- OpenAI Prompt Engineering Guide — practical guidance on prompt design to reduce hallucination risk
- IBM — What Are AI Hallucinations? — IBM’s definition and explanation of how hallucinations occur in language models
- Google Helpful Content Guidelines — Google’s framework for evaluating whether content demonstrates real expertise and experience
- Anthropic Prompt Engineering Documentation — Anthropic’s guidance on structuring prompts to improve accuracy and reduce confabulation

Independent AI Behavior Researcher
Soumen Chakraborty is the founder of AI Tools Usage Guide and an independent AI Behavior Researcher. His research examines how AI systems behave in practical workflows, with a focus on instruction-following failures, prompt reliability, hallucination risks, context loss, and output reliability.